大模型时代,知识真的平权了吗?
大模型时代,知识真的平权了吗?

ChatGPT、Claude、Gemini、DeepSeek……大模型一个接一个地涌现,而且还在快速进化。一个很自然的问题浮出水面:
我们是不是终于实现知识平权了?
答案可能没有想象中那么乐观。
更准确地说,大模型确实降低了”拿到答案”的门槛,但没有自动降低”用好答案”的门槛。
这两个东西差别很大。
进步是真实的
先说好的一面。大模型确实在做一些以前不可能的事:
以前想搞懂一个法律问题,要花钱请律师;想看病前做功课,要翻大量医学资料;偏远山区的学生遇到不会的题,身边没有好老师能问。现在,打开一个对话框,输入你的问题,几秒钟就能得到一个相当专业的初步回答。
语言壁垒也在被削弱。不懂英文的人,也能通过大模型高效获取英文世界的知识。理论上,一个县城中学的学生和北京四中的学生,可以获得同样质量的答疑服务。
这些进步是真实的,也是了不起的。
我自己最明显的体感是在读论文上。
以前读一篇英文论文,摘要、方法、实验、贡献点都得自己硬啃。现在我可以先让大模型帮我拆结构:这篇论文解决什么问题,用了什么方法,实验和 baseline 怎么设计,可能的缺陷在哪里。半小时内就能建立一个初步地图。
但问题也在这里:地图不是路。
模型能把论文讲顺,但它不能替我判断这篇论文和我的课题到底有没有关系,不能替我发现实验设计里哪些地方能迁移到自己的数据集,也不能替我把方法真正复现出来。
所以同样一篇论文,同样一个大模型,有的人只是拿到一段漂亮摘要,有的人能顺着摘要挖出一个可做的研究问题。差距没有消失,只是从”能不能读懂英文”转移到了”能不能提出下一步问题”。
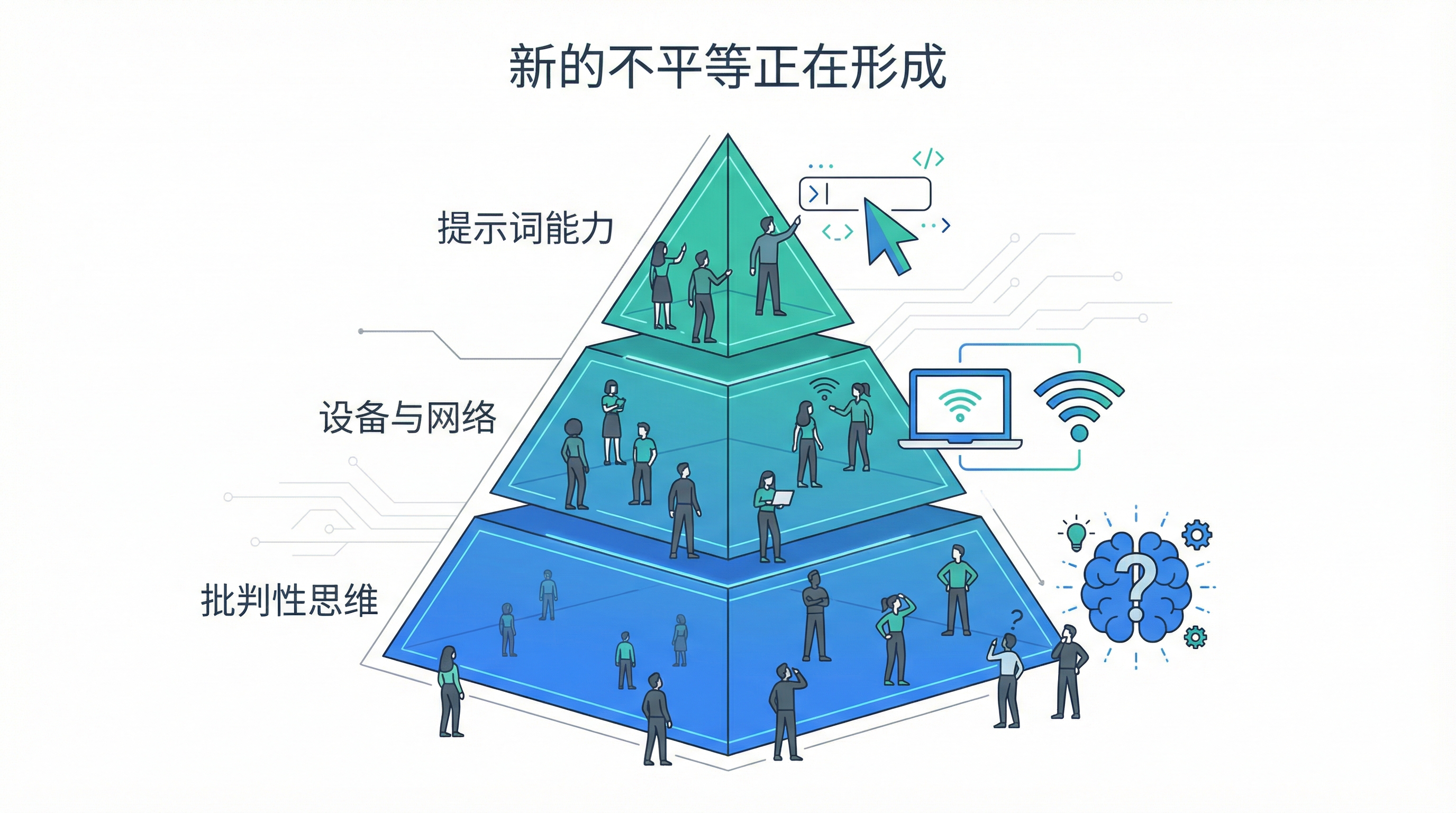
但新的不平等正在形成
问题是,工具的可及性只是知识链条上最表层的一环。大模型在拉平旧差距的同时,正在制造新的分层。
第一层:数字鸿沟依然存在。 你需要有设备、有网络,甚至需要”知道这个工具存在”。这听起来简单,但对很多人来说并不是。
第二层:”会问问题”本身就是一种稀缺能力。 同样一个大模型,一个懂得如何精准描述需求的人,和一个只会打”帮我写个东西”的人,得到的回答质量天差地别。提示词工程正在成为一种新的”元技能”——你得先会问,才能获得好答案。
第三层:付费墙制造新分层。 Claude Pro、GPT-4、Gemini Advanced……更强的能力往往藏在付费版本里。免费版够用吗?够,但天花板明显。这又形成了一道隐形的资源门槛。
第四层:批判性思维的差距被放大了。 大模型有一个特点——它输出错误信息的时候,语气和输出正确信息一样自信。能分辨对错的人,用它如虎添翼;全盘接受的人,可能比不用还危险。
这也是为什么我现在越来越少问”帮我总结一下”,而是改问:
- 这篇文章的核心假设是什么?
- 作者用了哪些证据支撑这个假设?
- 有没有可能存在反例?
- 如果我要复现,第一步该验证什么?
问题一具体,模型的价值就上来了。问题一空,答案也会跟着空。
一个精准的类比:图书馆
有人说,这就像图书馆。
公共图书馆是人类历史上最伟大的知识平权尝试之一。免费、开放、人人可进。但一百多年过去了,图书馆消除知识差距了吗?并没有。
原因很简单:真正决定一个人能从知识中获得多少的,不是”能不能接触到”,而是更底层的东西——
你知道自己不知道什么吗?(元认知)你有动力去主动探索吗?(内驱力)你能把碎片信息串成体系吗?(结构化思维)你愿意在困难的地方停留,而不是绕过去吗?(深度学习的耐心)
这些能力,图书馆给不了,大模型同样给不了。
一个更深的危险:知道得太容易了
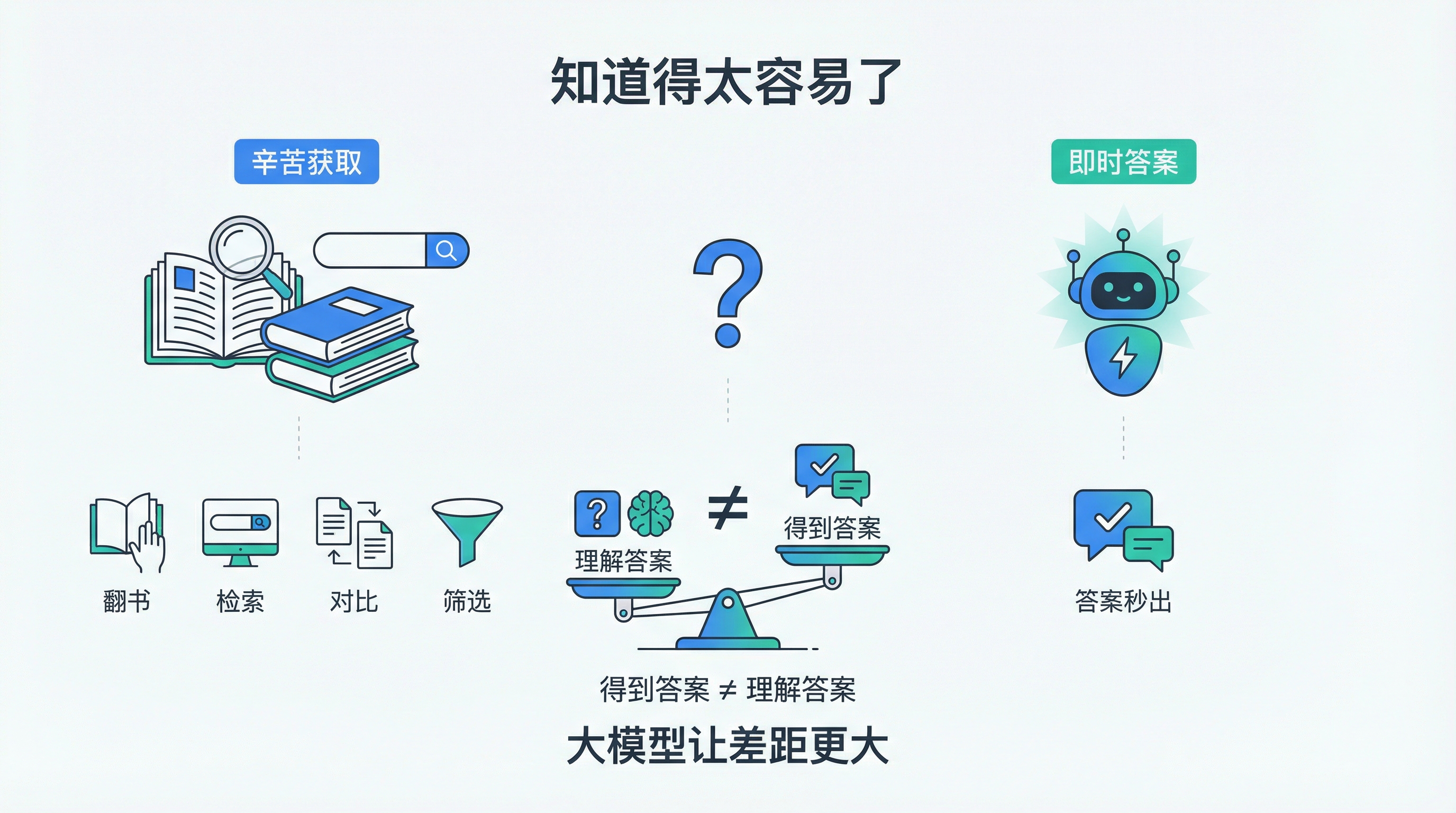
大模型时代还有一个容易被忽视的风险:它让”知道”变得太容易,反而可能削弱真正的”理解”。
以前查资料是有摩擦成本的。你得翻书、检索、对比、筛选,这个过程虽然笨拙,但它逼着你咀嚼和消化。现在答案秒出,很多人连问题都没想清楚就已经”得到答案”了。
得到答案和理解答案,是两件完全不同的事。
所以某种程度上,大模型可能会让差距更大——会用的人效率倍增,不会用的人只是多了一个更高效的”抄作业”工具。
知识平权 ≠ 信息平权
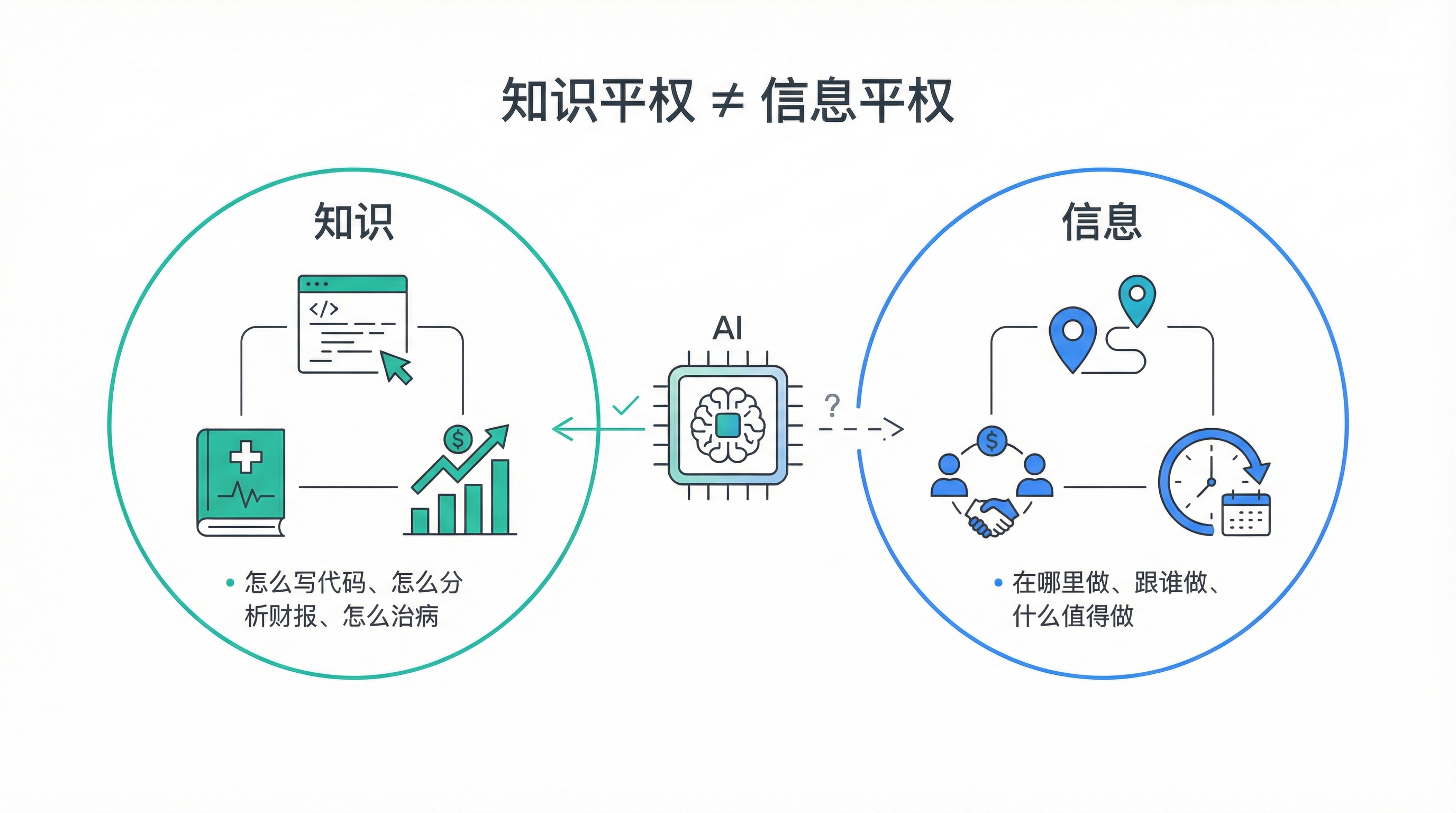
还有一个更锐利的区分值得注意:大模型让知识的获取更平等了,但并没有让信息变得平等。
知识是”如何做”——怎么写代码、怎么分析财报、怎么治疗某种病。这些大模型确实能教你。
但信息是”知道什么值得做、在哪里做、跟谁做”。这些东西往往藏在执行、关系和时间积累里,大模型帮不了你。
想想那些靠信息差赚钱的人:探店博主去吃了,你没吃;卖考研真题的人花时间收集了,你没收集;做个人IP的人坚持输出了两年,你没坚持;写论文的人读了两年文献,你没读。
他们变现的不是知识本身,而是不可被轻易复制的注意力投入。粉丝和客户买的也不只是信息,而是”这个人真的花了时间替我筛选过”的信任。
大模型能帮你读论文、写文案、分析数据,但它替代不了”你实际去做了这件事”这个事实本身。
真正的护城河是什么?
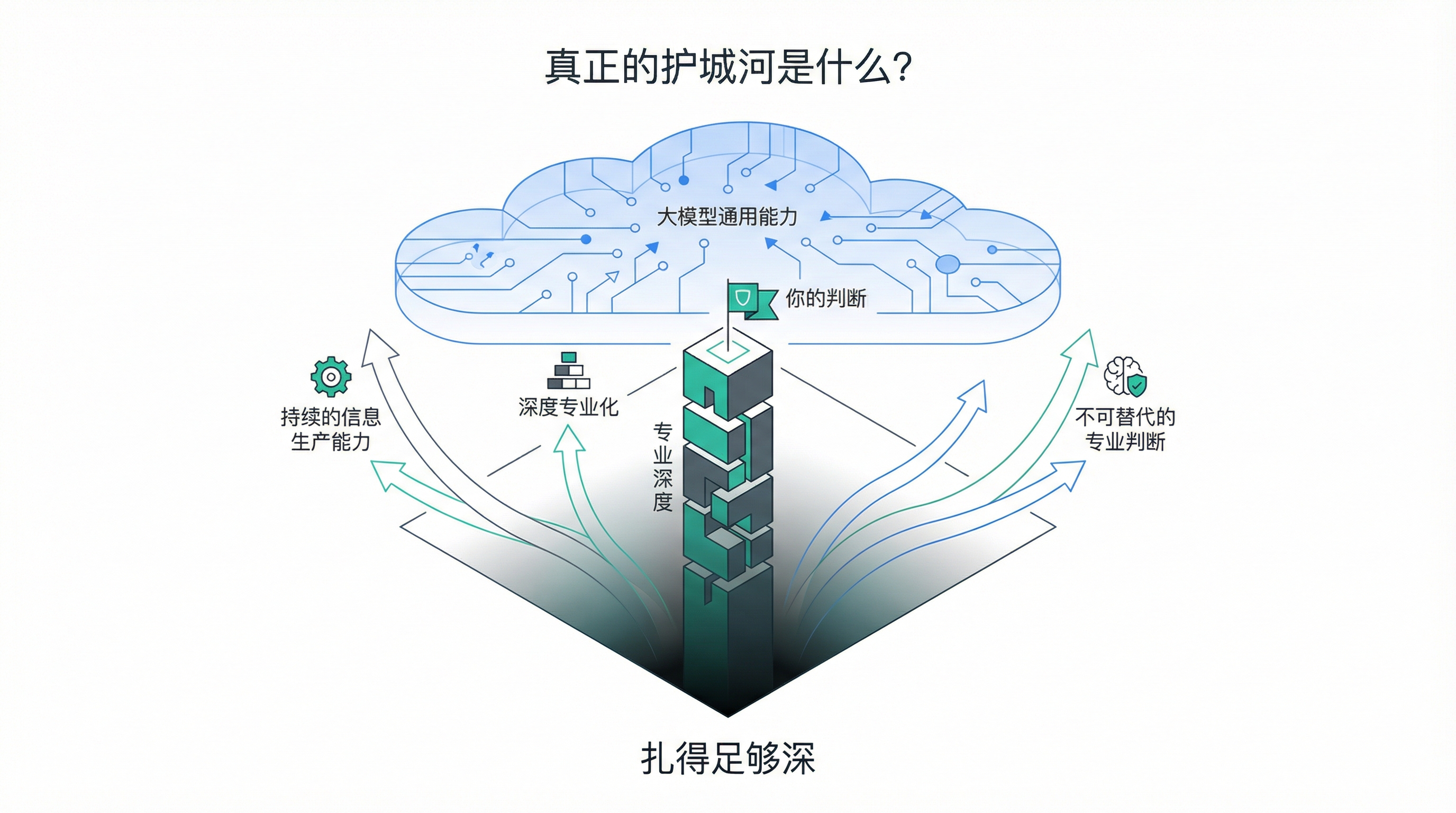
如果大模型让知识获取变得平等,那竞争的维度就会转移到别的地方。
不是”我知道你不知道的”,而是”我能持续知道你不知道的”。
一次性的知识套利会越来越不值钱。真正有价值的,是持续的信息生产能力——你能不断地在某个领域产出新的、经过验证的、别人还不知道的东西。
这就要求你在某个方向上扎得足够深,深到大模型的通用能力覆盖不了你的专业判断。
所以,大模型时代该怎么自处?
大模型把”信息高速公路”修到了更多人家门口,这是好事。但能不能开好车、开去哪里,差距依然巨大。
几个可能有用的思考:

善用工具,但别把平台当实力。 大模型是公共的,你能用,别人也能用。真正不可替代的,是你对某个领域的深刻理解、你积累的信任关系、你整合资源的能力。
刻意练习”问问题”的能力。 在大模型时代,提问能力可能比答案本身更重要。学会把模糊的直觉转化成精准的问题,这是一项值得投资的元技能。
警惕”充实的幻觉”。 每天和大模型聊很多,感觉学了很多,但回头一看什么都没沉淀——这是一个真实的陷阱。定期问自己:这周我真正理解了什么新东西?
选一个方向深扎下去。 通才的价值在下降,因为大模型本身就是最强的通才。未来属于那些在某个垂直领域深耕到大模型都帮不了的人。
如果要落到每天的动作上,我建议用一个很笨的方法:
每次用大模型学完一个东西,都强迫自己留下三样产物。
第一,一个 100 字以内的结论:我到底理解了什么。
第二,一个可验证的问题:我接下来要查什么、做什么、问谁。
第三,一个自己的判断:这件事和我当前目标有没有关系。
没有这三样,今天的对话大概率只是一次信息消费。
写在最后
大模型时代的知识平权,更像是一个半成品——
获取平等了,运用依然不平等。工具普惠了,能力依然分层。入口拉平了,出口依然分化。
说到底,人与人之间的差距,从来不是”能不能找到答案”,而是”能不能问出好问题”,以及”愿不愿意在找到答案之后,真正去做”。
这一点,一百年前图书馆没有改变,今天的大模型恐怕也不会。
如果这篇文章引发了你的一些思考,欢迎转发给身边同样在使用AI工具的朋友,一起聊聊。