
当我把AI的"缩放定律"迁移到人类学习上
今天读了OpenAI的经典论文《Scaling Laws for Neural Language Models》。
读完第一反应是:就这?跑了一堆实验,拟合了几条幂律曲线,也没什么高级的数学推导,凭什么成为大模型领域的奠基之作?
但仔细想想,这篇论文的经典之处恰恰在于——它用一个简单的规律,改变了整个AI行业的方向。
论文到底说了什么?
一句话概括:
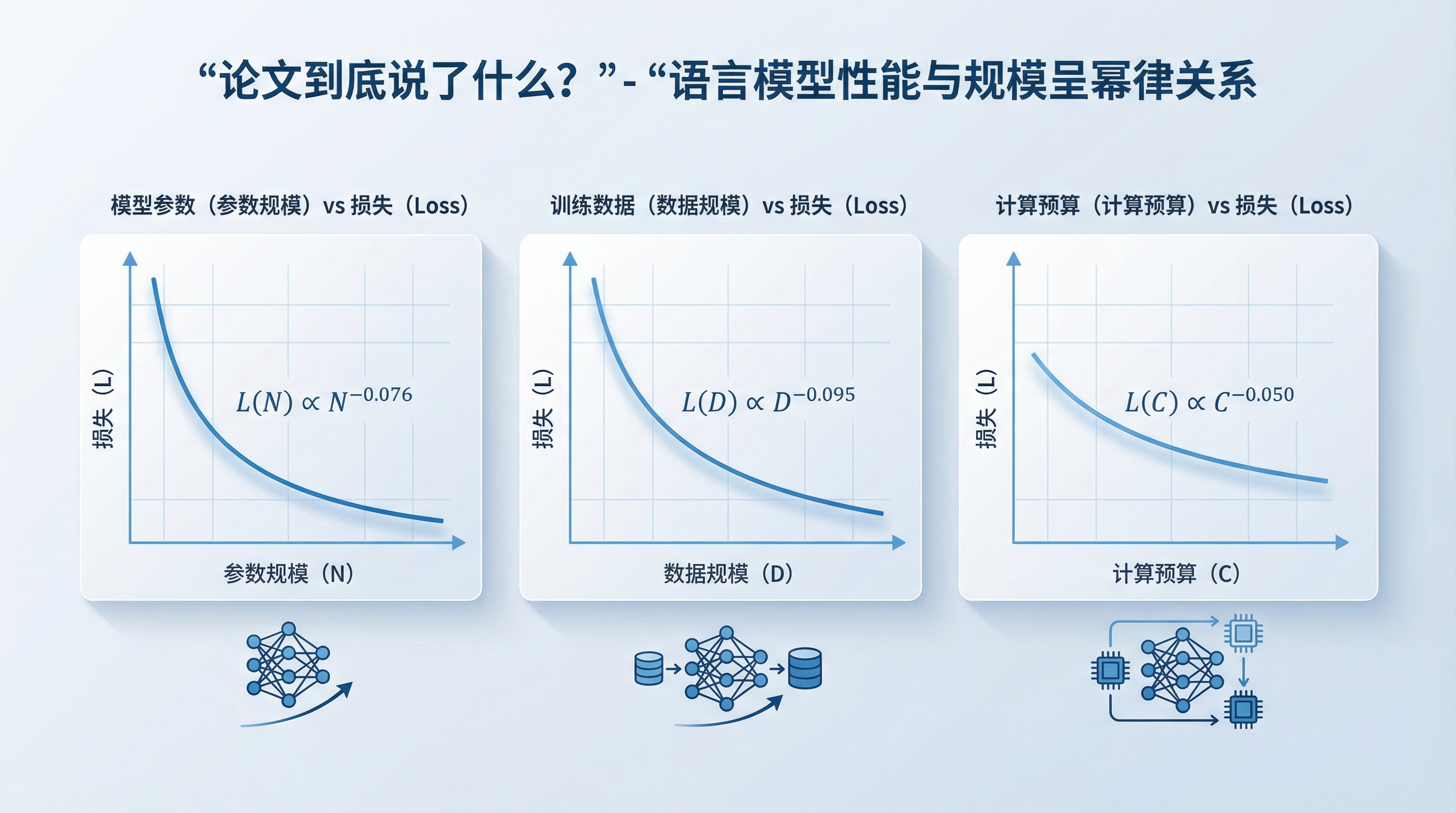
语言模型的性能,与模型规模、数据量、计算量呈幂律关系。规模越大,效果越好,而且是可以预测的。
三个核心公式:
| 关系 | 公式 | 意思 |
|---|---|---|
| 参数规模 | L(N) ∝ N^-0.076 | 参数翻倍,损失降5% |
| 数据规模 | L(D) ∝ D^-0.095 | 数据翻倍,损失降6.6% |
| 计算预算 | L(C) ∝ C^-0.050 | 计算翻倍,损失降3.4% |
看起来很朴素对吧?但就是这些简单的幂律关系,回答了一个所有人都想知道的问题:
“扩大规模到底值不值?”
在这篇论文之前,没人敢确定。在这篇论文之后,整个行业开始疯狂卷规模——GPT-3、GPT-4、LLaMA、PaLM……所有大模型的训练策略,都直接或间接基于这篇论文的发现。
最反直觉的结论
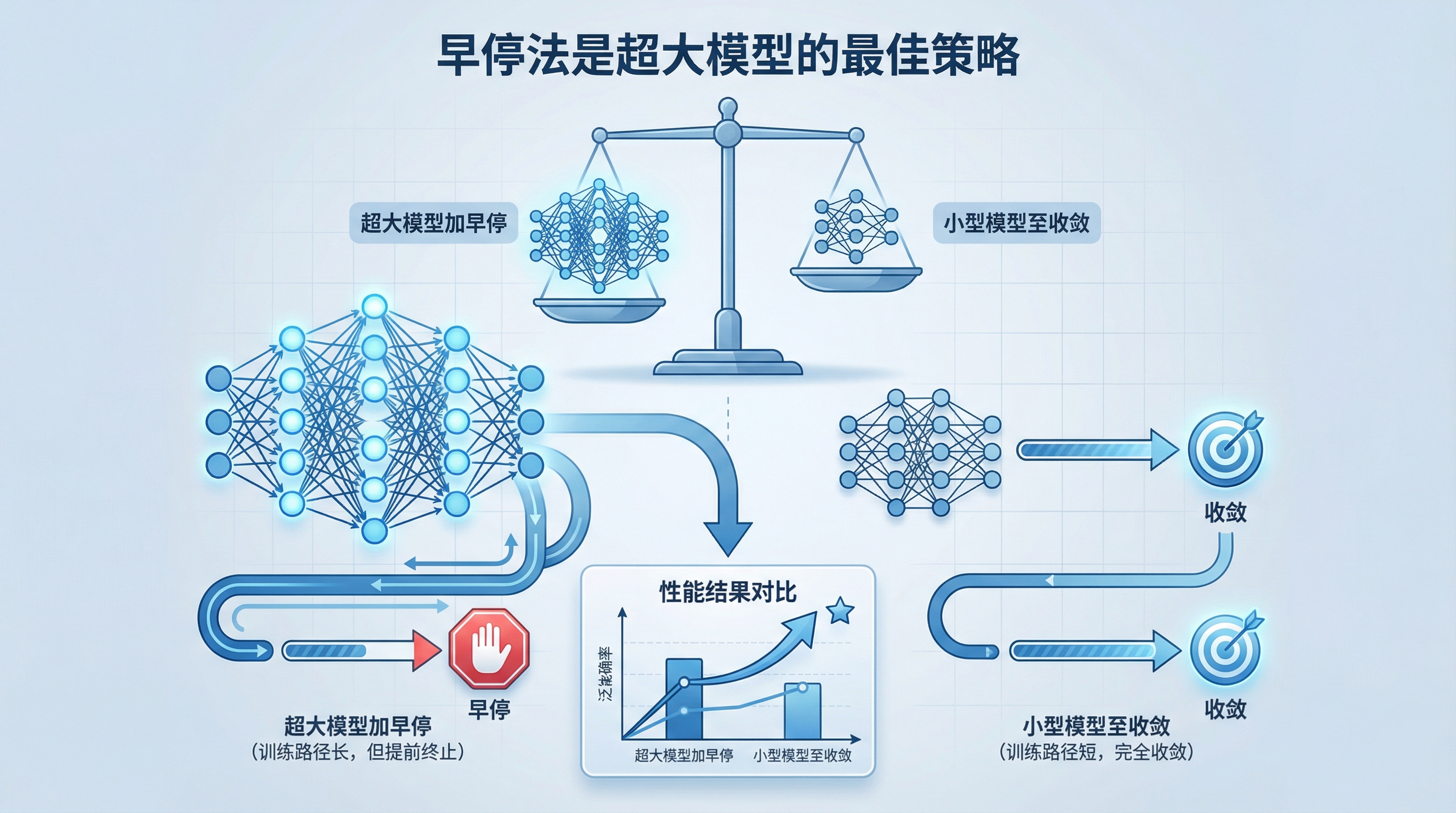
论文里有一个让我印象很深的发现:
训练到收敛是低效的。最优策略是:训练超大模型,然后提前停止。
这完全颠覆了当时的直觉——大家都觉得”训练越久越好”。但论文用数据证明了:
大模型 + 早停 > 小模型 + 训练到底
在固定计算预算下,与其把一个小模型训练到极致,不如训练一个更大的模型,然后在它还没完全收敛时就停下来。这样反而效果更好。
这个发现直接指导了GPT-3的训练策略。
我开始想:人类学习是不是也有”缩放定律”?
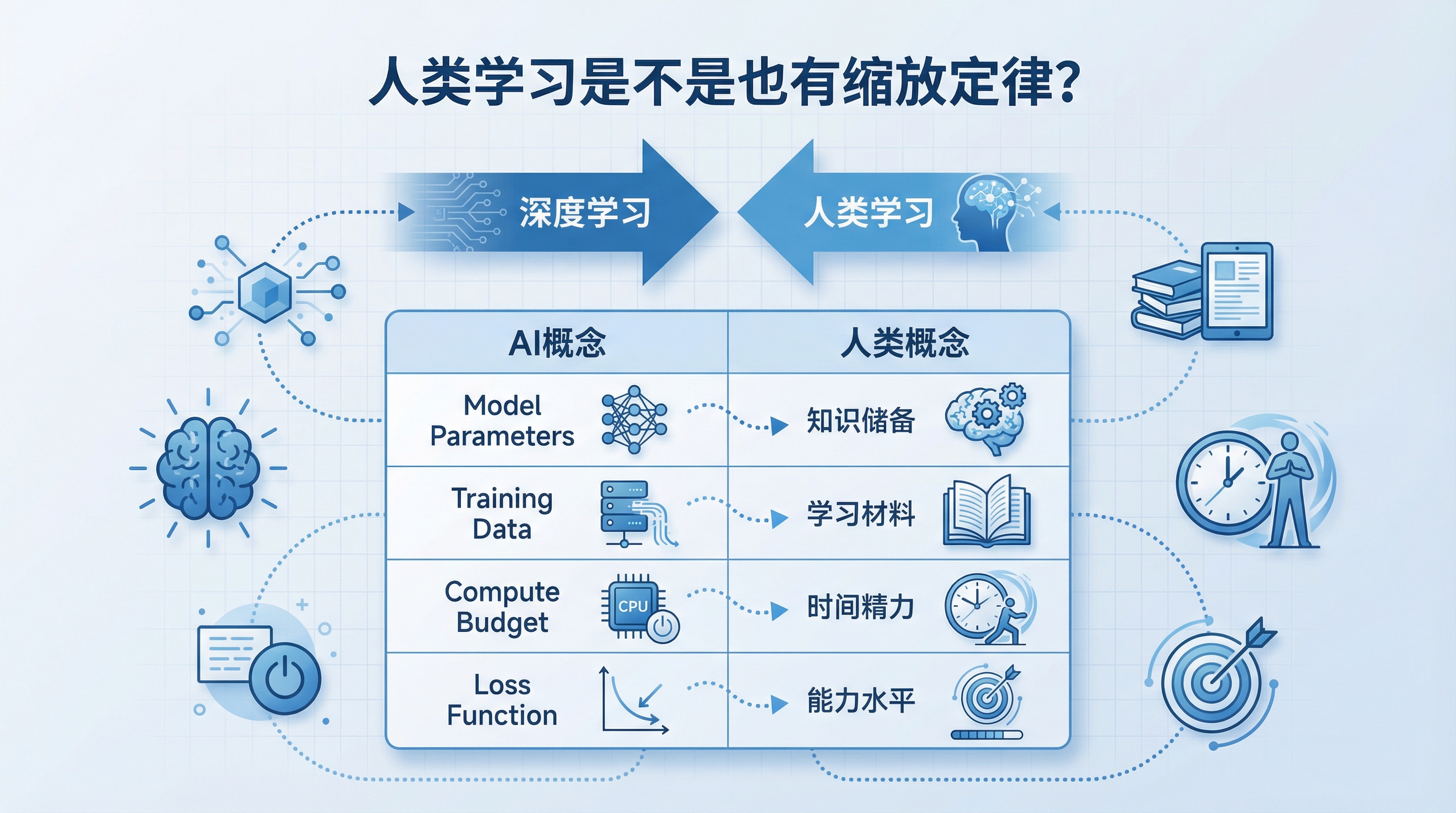
如果把深度学习的概念迁移到人类学习上:
| 深度学习 | 人类学习 |
|---|---|
| 模型参数 N | 知识储备/认知框架 |
| 训练数据 D | 学习材料/人生经历 |
| 计算预算 C | 时间和精力 |
| 损失函数 L | 能力水平/解决问题的效果 |
然后我发现,这篇论文的几个核心发现,对人类学习竟然也有启发。
启示一:知识越多,学新东西越快
论文发现:参数越多的模型,学同样的东西需要的数据越少。 大模型更”样本高效”。
对应到人,就是:
知识储备越多,学新东西越快。
这不是说”聪明人学得快”,而是知识之间的连接让你能快速理解新概念。
懂编程的人学新语言,比从零开始快得多。懂经济学的人看政策新闻,比普通人理解更深。懂历史的人看国际局势,能快速找到参照系。
前期积累看似慢,但会加速后续学习。
这让我想到一个比喻:知识就像一张网。网越大,新知识越容易被”捕获”进来。网越小,新知识就像流沙一样滑走。
启示二:广度学习 + 适度深入 > 单一领域死磕
论文最核心的结论是:大模型 + 早停 > 小模型 + 训练到底。
对应到人类学习,就是:
广度覆盖多个领域,每个领域学到”够用”就停,比单一领域死磕到底更有价值。
这挑战了”一万小时定律”——不是所有领域都需要精通到收敛。
学编程,掌握核心概念后转战其他领域,比死磕某个框架更有价值。学语言,能交流就够了,不必追求母语级。学投资,理解核心原理就行,不必成为巴菲特。
人的”计算预算”(时间精力)是有限的。把预算分配给多个领域,每个领域学到”边际收益递减”的点就切换,整体收益更高。 这让我重新思考”专精”和”广博”的平衡。也许最优策略不是”在一个领域深耕一万小时”,而是”在多个领域各投入几百小时,形成知识网络”。
启示三:只读书不实践 = 过拟合
论文里有一个过拟合方程:
L(N,D) = [(Nc/N)^(αN/αD) + Dc/D]^αD
意思是:模型太大、数据太少,就会过拟合——记住训练数据但无法泛化。
对应到人:
知识储备丰富但经历单一,容易”钻牛角尖”。
读了很多书但没实践 → 纸上谈兵。只在一个领域深耕 → 看什么问题都用那个领域的视角。
知识规模(N)和经历多样性(D)需要同步增长。
这让我意识到:学习不能只停留在”输入”层面。读书、听课、看视频,都是在增加N(知识储备)。但如果没有足够的D(实践经历),就会过拟合——考试能拿高分,但遇到真实问题就傻眼。
启示四:学习方法不如学习量重要
论文还有一个发现:模型架构(深度、宽度、注意力头数)在合理范围内影响很小。 真正决定性能的是规模。
对应到人:
学习方法不如学习量重要。
各种”高效学习法”——番茄钟、费曼技巧、间隔重复、思维导图——就像模型的架构细节。有用,但不如多学多练带来的提升大。
这让我释然了。之前总在纠结”最优学习方法”,试了各种工具和技巧。但也许先学起来,量上去了一切都好说。
当然,这不是说方法没用。而是说,在规模不够的时候,纠结方法是本末倒置。
启示五:知道什么时候”早停”
Scaling Law是幂律关系,特点是:
- 投入翻倍,收益递减(不是线性)
- 但永远不会到零
学一个领域:
- 前100小时:快速上手,收益最大
- 100-1000小时:稳步提升
- 1000小时后:边际收益变小
启示:知道什么时候该”早停”。
当在一个领域的投入产出比,低于转向新领域的收益时,就该切换了。不是放弃,而是”早停”——把精力分配到下一个领域。
总结:人类学习的缩放定律
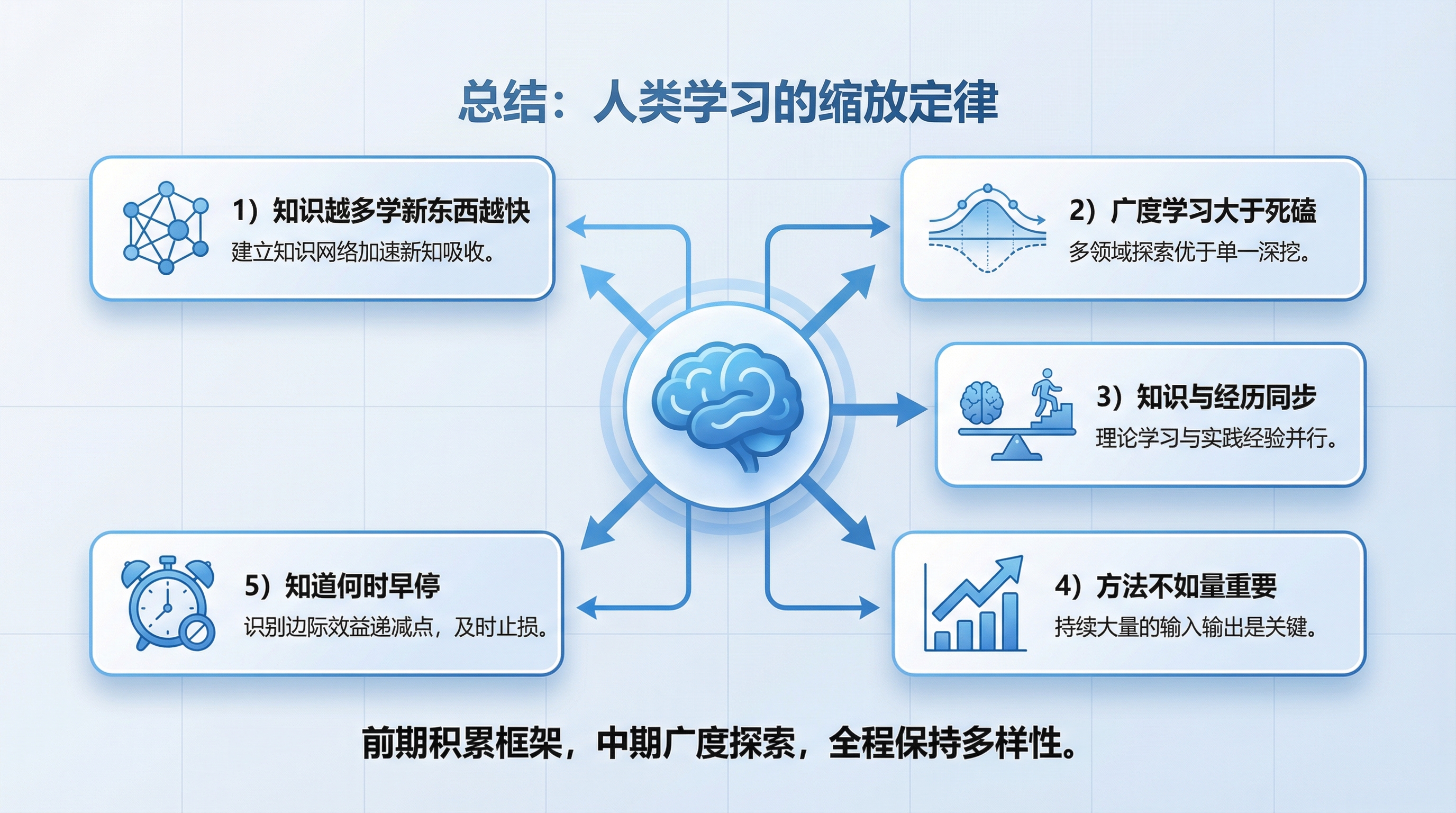
读完这篇论文,我试着总结一个”人类学习的缩放定律”:
| 论文发现 | 个人学习启示 |
|---|---|
| 大模型更样本高效 | 知识越多,学新东西越快 |
| 大模型+早停最优 | 广度学习 > 单一领域死磕 |
| N和D要同步增长 | 知识和经历要同步积累 |
| 架构不如规模 | 方法不如量重要 |
| 幂律递减 | 知道何时”早停” |
一句话概括:
前期积累知识框架(增大N),中期广度探索(早停策略),全程保持输入多样性(避免过拟合)。
写在最后
这篇论文之所以经典,不是因为它发明了什么高级技术,而是因为它发现了一个简单的规律,然后整个行业都按这个规律走了。
有点像摩尔定律——本身不是技术突破,但它指导了芯片行业几十年的发展方向。
而当我把这个规律迁移到人类学习上,发现它依然有启发意义。
也许,学习的本质就是不断扩大自己的”模型规模”,同时保持”训练数据”的多样性,在合适的时机”早停”,把精力分配到下一个领域。
规模是可预测的。学习也是。
今天读了《Scaling Laws for Neural Language Models》,写下这些思考。





