
研路炼钢 | 从卖产品到卖技能——一顿火锅,我把 Agent 的底层逻辑又梳理了一遍

昨天和一个做产品的朋友吃饭。八两的帝王蟹端上来的那一刻,我们聊的话题已经从”他要做什么产品”转到了”他要做什么技能”。
这个转向本身就值得记一下。
一、从”卖产品”到”卖 Skill”,中间那一步是什么
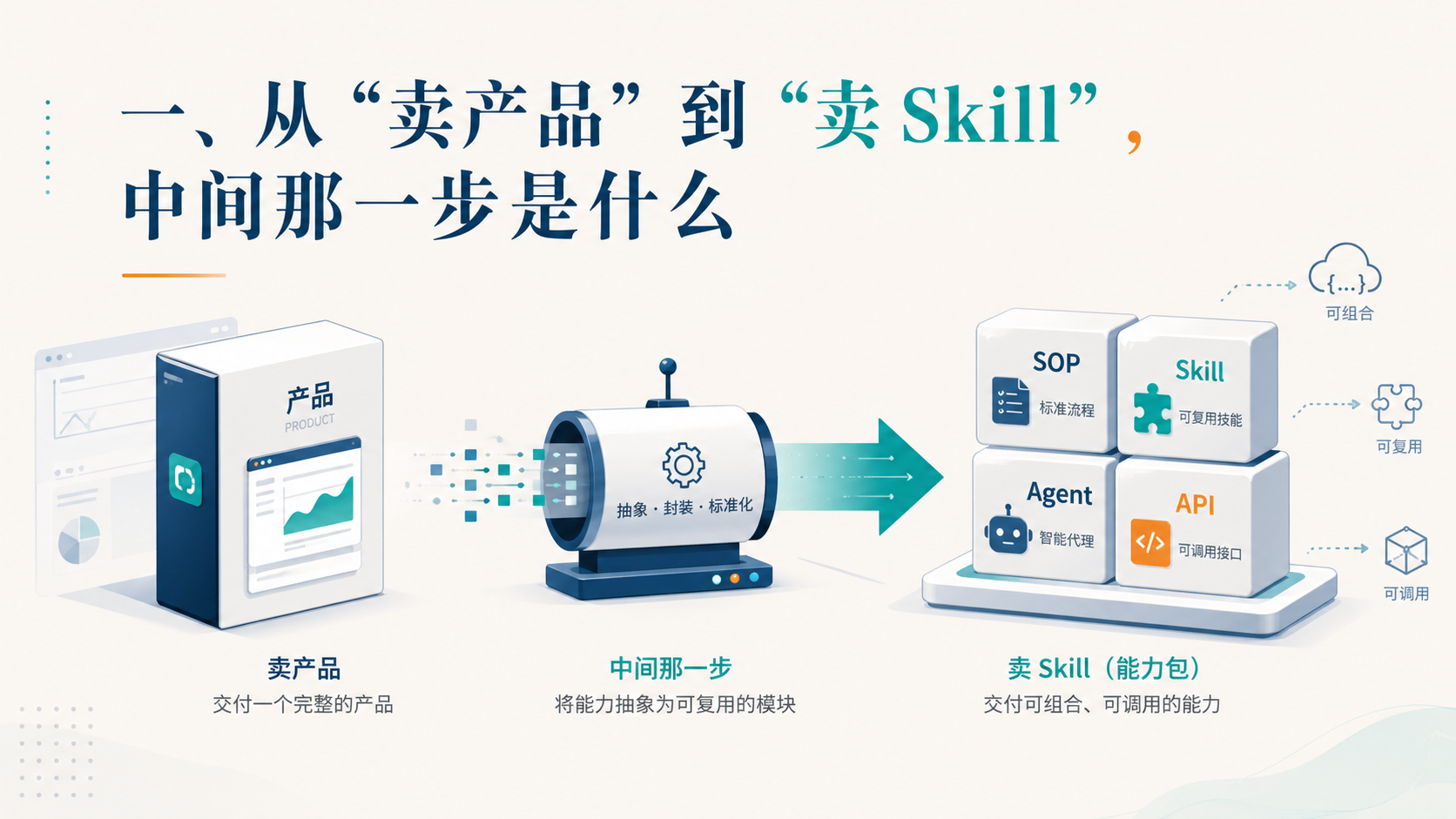
他过去一直想做一个产品出来卖。这次见面,他的方向变了——他想做一个 Skill 来卖。
这两件事看起来像同一件事,差别其实很大。
卖产品,你卖的是一个能直接被使用的东西。卖 Skill,你卖的不是 Skill 本身——Skill 没法独立存在,它必须绑定脚本,绑定 Agent,才能跑起来。所谓卖技能,本质上卖的是 API 能力包:一段被规范化、被工程化、被可调用化的能力。
为什么这个转向在这两年突然变成显学?因为 Claude Code、Codex、Kimi 这一批 Agent 产品出来之后,大家发现”能力”是可以被封装的,而封装出来的东西有人愿意付费。
但卖 Skill 有个隐含前提:你得真的把一套流程跑通过、抽象过、压缩过。否则你卖出去的就是一个空壳子。
二、95% 的时间不是在写代码

我最近又在系统学 Agent 相关的东西,把 Kimi、Codex、Claude Code 这些产品的内部逻辑都过了一遍。结论很扎实——
它们底层都是同一套东西:SDD,规范驱动开发(Spec-Driven Development)。 差异只在细节实现,框架是一样的。
这件事的反直觉之处在于:搭一个 Agent,95% 的时间不是在编程。
那 95% 的时间在干嘛?
在做需求梳理。在把一个模糊的”我想做 X”拆解成”先做 A,再做 B,然后做 C,每一步的输入输出和约束分别是什么”。在反复确认每一个子任务的边界。
代码是最后那 5% 的事——而且很多时候那 5% 就是把已经梳理好的规范翻译成可执行的形式。
这件事说穿了不新鲜,但被 Agent 这个语境重新命名之后,它的意义变了:以前规范是给人看的文档,现在规范是给模型跑的代码。 规范本身就是开发产物。
三、子代理:手动划分,还是自动生成
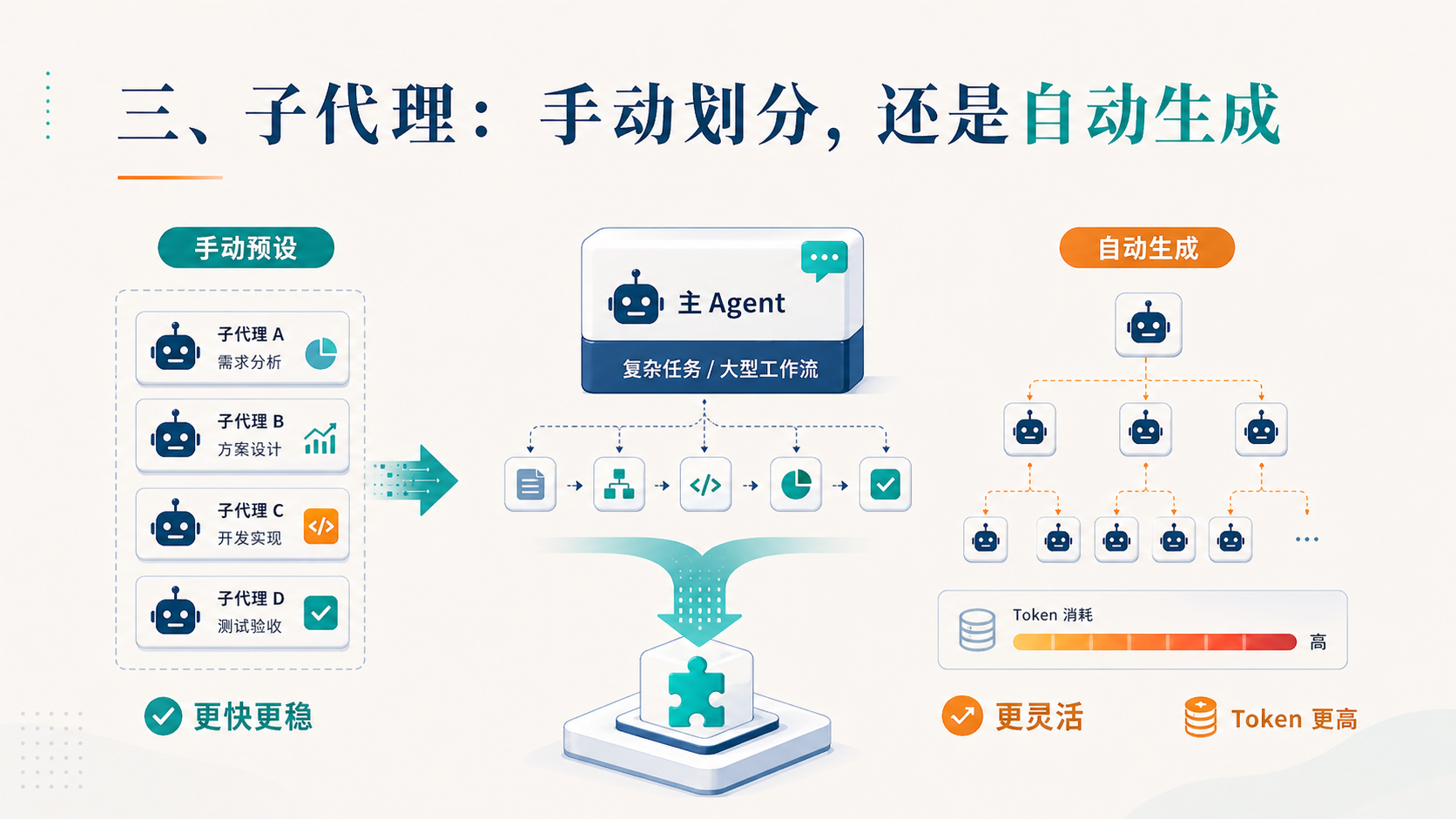
需求梳理完之后,要把一个大 Agent 拆成若干个子代理(sub agent)——这是规范驱动开发的标准动作。
每个子代理只做一件事。一个负责收集信息,一个负责处理信息,一个负责部署落地。人也是一样:一个人只做一件事会很专注,做几十件事就废了。 Agent 不过是把这个常识工程化了。
这里有一个绕不过去的选择:子代理是手动创建,还是让平台自动生成?
像 Codex 这类工具,会自动帮你把子代理拆出来。看起来很爽,但代价是——它会消耗大量 Token,因为每一次自动拆分都意味着模型要重新理解上下文、重新规划路径。
更经济的做法是反过来:预设好你的子代理。把每一个角色定义清楚——它做什么、不做什么、用什么模型、走什么流程——然后跑的时候直接调用。
预设好的版本,跑起来又快又便宜。代价是你前期得花时间手动设计这些角色。
这是一个典型的”前期成本换长期效率”的工程权衡。如果一个工作流你要重复跑成百上千次,显然预设更划算;如果你只是探索性地试一次,自动拆分更省人力。
四、Token 经济学:让专业的人做专业的事
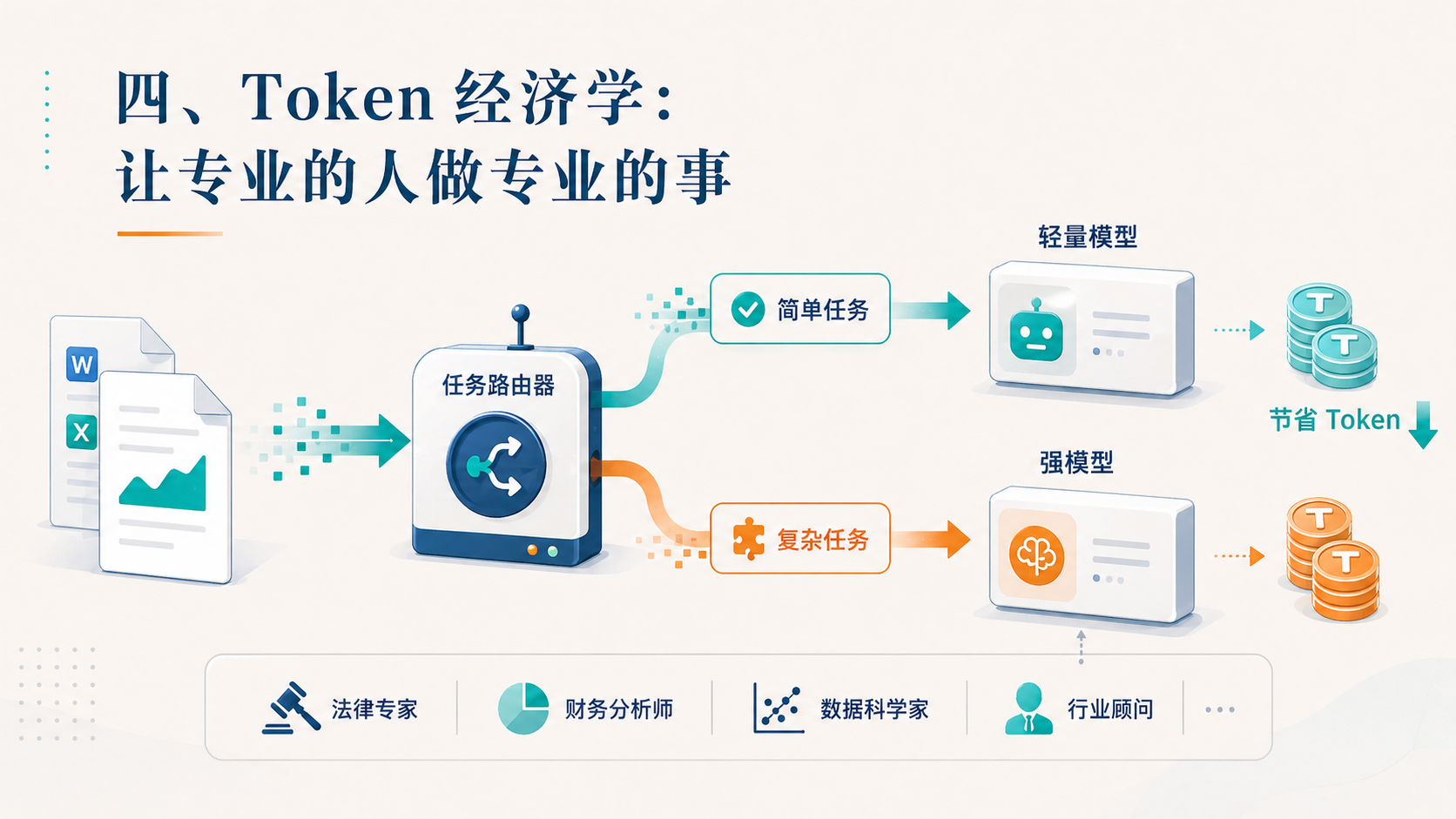
聊到这里,他给我抛了一个新词,叫**”Token 经济学”**。
意思也很简单:一个项目里有很多文件,但不是所有文件都需要被丢给大模型。只有那些真正需要模型推理的部分,才值得花 Token。
这件事的衍生原则是:简单的问题用便宜的模型,难的问题用贵的模型。
如果一个任务里既有简单部分又有复杂部分,正确的做法不是”全用最强的模型一把梭”,而是把它拆成五六个小问题,然后给每个小问题分配合适的模型。
这背后其实是一种很朴素的工程哲学——让专业的人做专业的事。
我前几天有个本科学弟来问我接 DeepSeek API 为什么不能生图。我第一反应是:你为什么会觉得 DeepSeek 能生图?它是文本模型,不是视觉模型。
模型本身是分类的。文本模型背后是 MoE(Mixture of Experts)架构,你启动一次推理,实际是若干个”专家”在分工处理上下文。模型选型这件事,在 Agent 时代的重要性比单纯调一个模型要高得多——因为你要为每一个子任务挑一个对的工具。
不挑,你就在用最贵的扳手拧最便宜的螺丝。
五、SOP → Skill → Agent → 独立程序
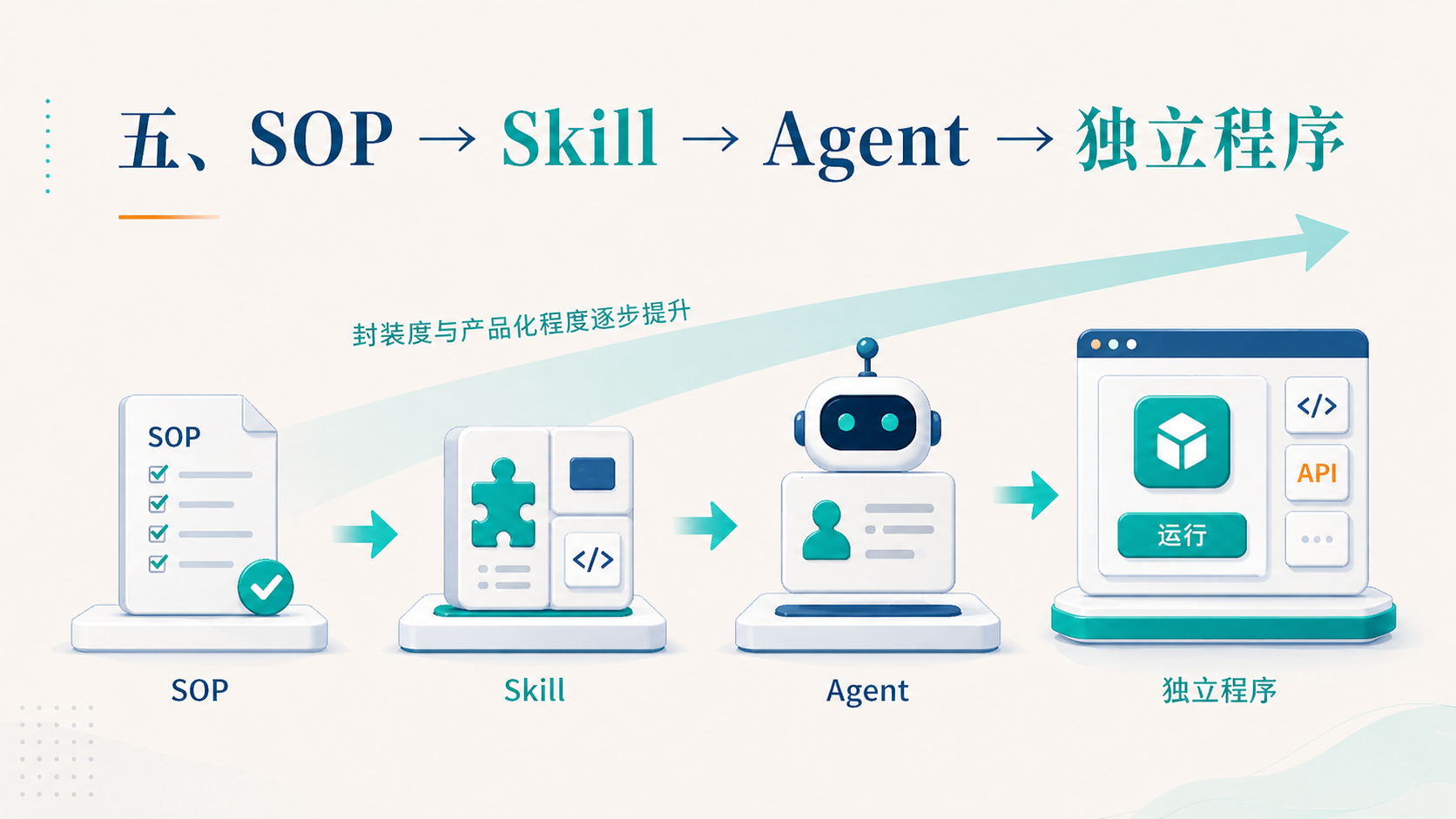
朋友给我讲的最有启发的一段是这个——一整套流程,你可以一层一层往上压缩。
第一层是 SOP(标准作业程序)。一个完整的、可以人工执行的流程。
第二层是 Skill。把这个 SOP 编码成一个可被模型调用的能力包,这就是技能。
第三层是 Agent。给这个 Skill 包一层”角色”:它叫什么、负责什么、配合谁、用什么模型。
第四层——也是最关键的一步——把整个 Agent 工作流压缩成一个独立的可运行程序。
到这一步之后,你不再需要每次去启动那个 Agent、不再需要每次去喂上下文,你只需要运行那个程序就行。
Skill 是 SOP 的工程化,Agent 是 Skill 的人格化,独立程序是 Agent 的产品化。
每往上压缩一层,门槛降低一级,使用频率高一级。最终交付到用户手里的,可能是一个命令行工具、一个网页按钮、一个 API 端点——但它背后是一整套被层层封装的能力。
这件事对我个人的意义在于:我现在在做的事——读论文、写专利、做实验、跑竞赛——其实都可以用这套思路重做一遍。把每一个我重复在做的流程,沉淀成 SOP,再压成 Skill,再封成可执行的工具。
六、底层和应用层,双管齐下
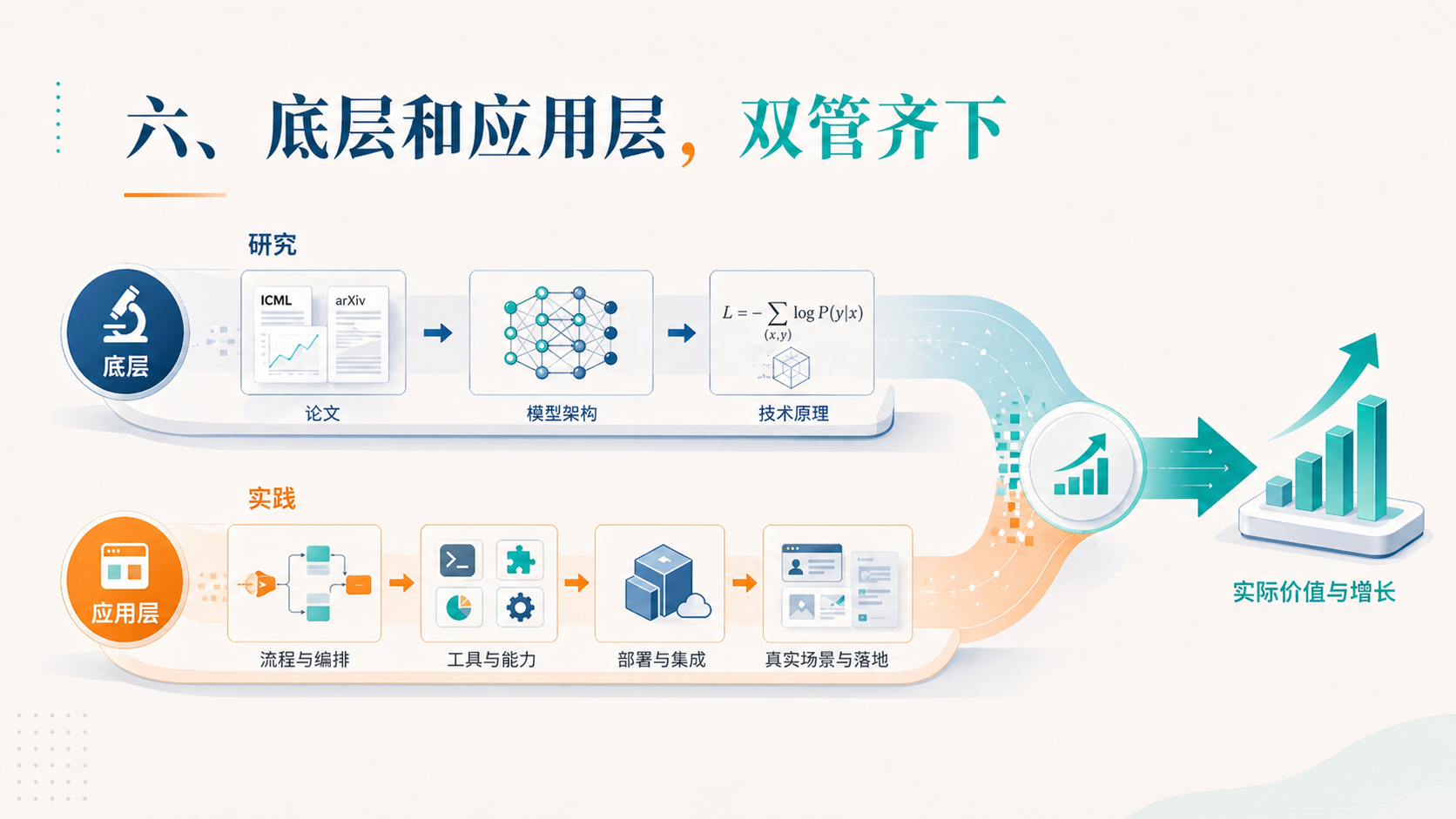
聊到最后,我跟他说了一句我自己也有点意外的话:了解底层这件事,可能没我之前以为的那么重要。
更重要的是怎么用。是辩证地用。是知道在什么场景下用什么模型、什么 Skill、什么 Agent。
底层当然要懂——不懂的话你连工具书都读不下来。但底层的边际收益是递减的:你看了第一篇 Transformer 论文,认知会大涨;看到第十篇相关论文,大部分时候是在重复确认你已经知道的东西。
应用层不一样。应用层每多用一次工具、多搭一个工作流,你的”工程肌肉记忆”就厚一层。这个东西没法靠看论文获得,只能靠跑。
所以我现在双管齐下——一只手研究底层的内部逻辑,一只手疯狂搭应用、疯狂用工具。两边都不放手,但心里清楚:在当下这个阶段,应用层的产出更接近真实回报。
写在后面

这篇东西本来是吃饭的时候随口聊的。回来之后我把对话录音过了一遍,发现里面真正有价值的内容,大概就是这六块。
帝王蟹很好吃,但帝王蟹两天之后就忘了。这套框架记下来,半年之后还能用。
下一步我打算搭一个全职的 Agent——SDD 驱动,子代理预设,模型分级,Token 经济。等我把这套东西跑通了,再写一篇详细的实操记录。
——研路炼钢









