

读完 6 个巨富的金钱观,我一个研究生想了很多
最近读了一些关于洛克菲勒、巴菲特、福特、卡内基、比尔·盖茨、马斯克的金钱观。 本来只是随便翻翻,但越看越觉得有意思——不是因为他们有多少钱,而是因为他们对钱的理解,和我们普通人完全不一样。 我一个月奖学金几千块的研究生,聊巨富的金钱观可能有点搞笑。但有些道理跟你有多少钱没关系,跟你怎么看待钱有关。 福特那句话,戳到我了 福特说过:”如果金钱是你获得独立的希望,你将永远也不会得到独立。在这个世界上,一个人所能拥有的唯一真正的安全保障,就是知识、经验和能力的储备。” 这句话让我想了很久。 作为一个研究生,我现在的经济状况就是”基本够用但没有余裕”。以前我会想,等以后赚够了钱就安全了。但福特说的是:钱可以贬值、可以损失、可以被各种意外吃掉,唯一不会被拿走的是你脑子里的东西。 知识、经验、能力——这些才是真正的安全感来源。不会贬值,不会被偷走,而且越用越值钱。 想通这一点之后,我对读研这件事的心态变了。以前觉得读研是延迟赚钱,现在觉得读研就是在投资自己——用两三年时间换一套别人拿不走的能力。这个回报率,比任何理财产品都高。 巴菲特:越早开始越好 巴菲特的核心观点很简单:开始存钱并及...
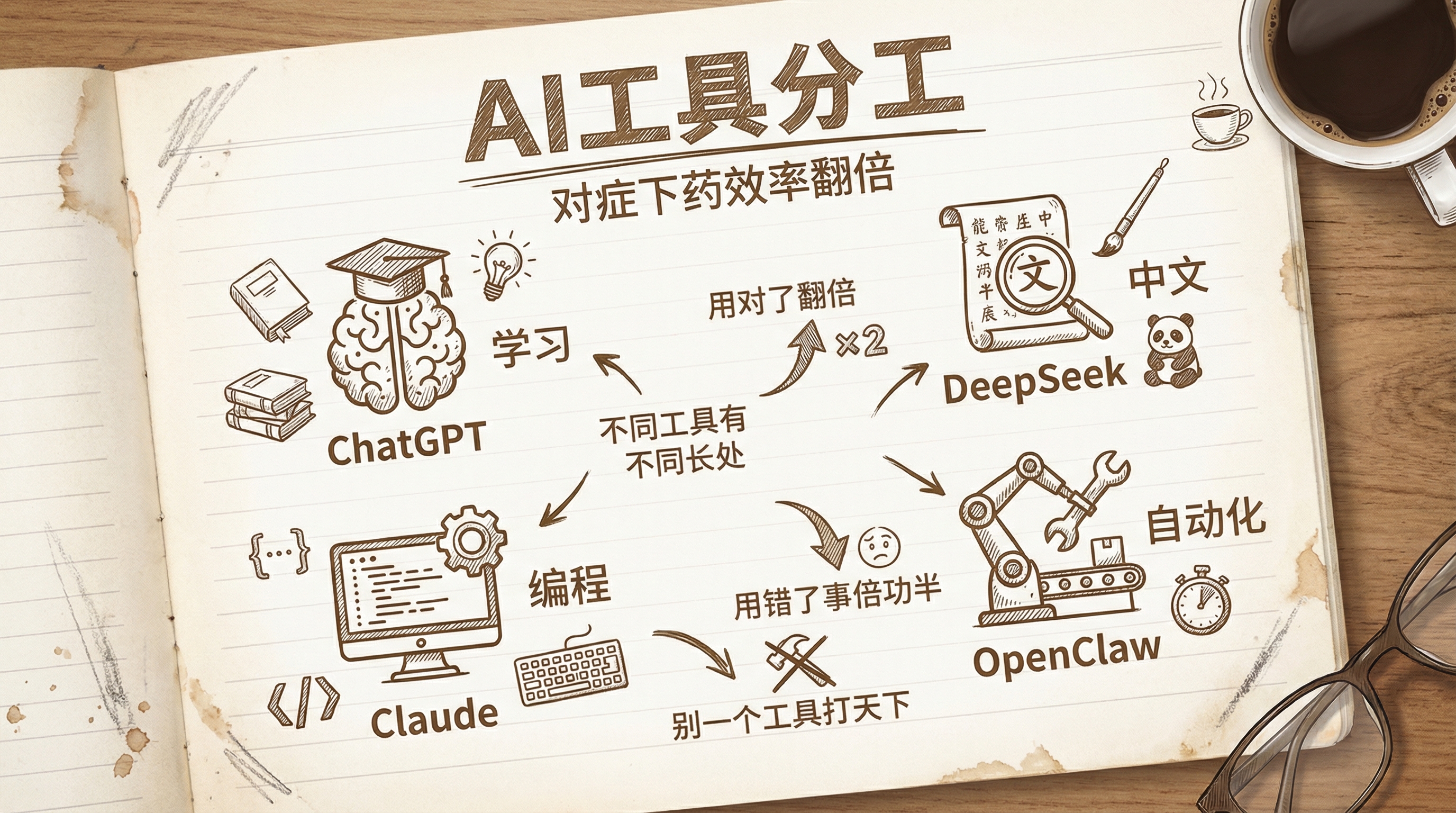
这么多 AI 工具,我是怎么分工的
我现在每天同时用好几个 AI 工具:Claude Code、Gemini CLI、Kimi、DeepSeek、ChatGPT、OpenClaw…… 刚开始的时候很混乱,什么事都问 ChatGPT,有时候效果好有时候效果差,也说不清为什么。后来慢慢摸出来一个规律:不同的工具有不同的长处,用对了效率翻倍,用错了事倍功半。 今天分享一下我自己的分工方式。不一定适合所有人,但至少是我实际验证过的。 我的分工逻辑 想通一个概念、学一个新东西 → ChatGPT ChatGPT 的知识面最广,解释能力最强。你问它一个你不懂的概念,它能用你能理解的语言讲清楚,还能根据你的追问不断深入。 我读论文遇到不理解的方法时,第一个问的就是它。不是让它帮我读论文,而是让它帮我理解论文背后的原理。 写代码、调 bug → Claude Code / Gemini CLI 写代码这件事,我目前的体感是 Claude Code 和 Gemini 都很强,各有优势。Claude Code 在理解复杂上下文方面更好,Gemini 在快速生成和调试方面效率高。 我的习惯是用 Claude Code 做比...

华罗庚 70 年前说的两句话,我到现在才真正听懂
1956 年,华罗庚在北京大学做了一场演讲。 核心就两句话:聪明在于学习,天才在于积累。 70 年前的道理,今天听起来还是觉得扎心。不是因为道理老了,是因为我们还是没做到。 “他天生就聪明,我比不了” 你是不是也这么想过? 看到别人发了顶会,觉得人家就是聪明。看到别人代码写得快,觉得人家就是有天赋。 华罗庚不同意。 他初中数学并不好,被老师批评过。他后来回忆说:”我小时候并不聪明,只是比别人多用了一些时间。” 他所谓的”多用时间”是什么概念?别人每天学一小时,他学三小时。别人做一道题,他做十道。别人遇到难题跳过去,他反复琢磨到想通为止。别人坚持几个月就放弃了,他坚持了一辈子。 他的”聪明”不是天赋,是时间的累积。 只不过这个过程别人看不到。 天才的真相 华罗庚说:”天才在于积累。” 这句话我以前觉得是鸡汤,最近才真正体会到它的意思。 我从去年开始每天读一篇论文。刚开始很痛苦,一篇 DETR 的论文能啃三天,读完了也说不清楚核心思路。但读到第 30 篇的时候,我发现自己看新论文的速度快了很多——不是因为我变聪明了,而是积累到了一个临界点,很多概念已经不需要重新理解了。 这就是...

如果 70 岁的你给现在的你写一封信
前段时间看到一个问题:如果 70 岁的你能给 20 岁的自己写一封信,你会说什么? 一位 70 岁的长者给出了 5 条建议。每一条都很朴素,但仔细想想,又觉得扎心。 不是什么新道理,但有些道理就是要被戳很多次才能真的听进去。 别老翻过去的账了 你是不是也经常这样:反复回想曾经的失败,后悔当时为什么没做另一个选择,脑子里不断循环”如果当时……”。 心理学上把这叫”反刍思维”。研究表明,每次回想过去的失败,大脑的反应跟你真正经历失败时是一样的——等于你把同一件痛苦的事经历了一百遍。 过去已经发生了,改不了。反复回放不是反思,是自我折磨。 我自己也有过这种阶段。去年两个国赛都拿了三等奖,当时很不甘心,连着好几天都在想”如果那个环节再多准备一下就好了”。后来发现这种想法除了让自己更难受之外,什么都改变不了。 过去是学费,不是包袱。学费交了就交了,背着它走只会更慢。 别提前预支明天的痛苦 担心明天的答辩、担心下个月的论文进度、担心毕业后找不到工作。 但研究数据说,85% 你担心的事永远不会发生。剩下 15% 发生了的,大部分你也能应对。 担心不会改变结果,只会消耗你今天的精力。你在焦...
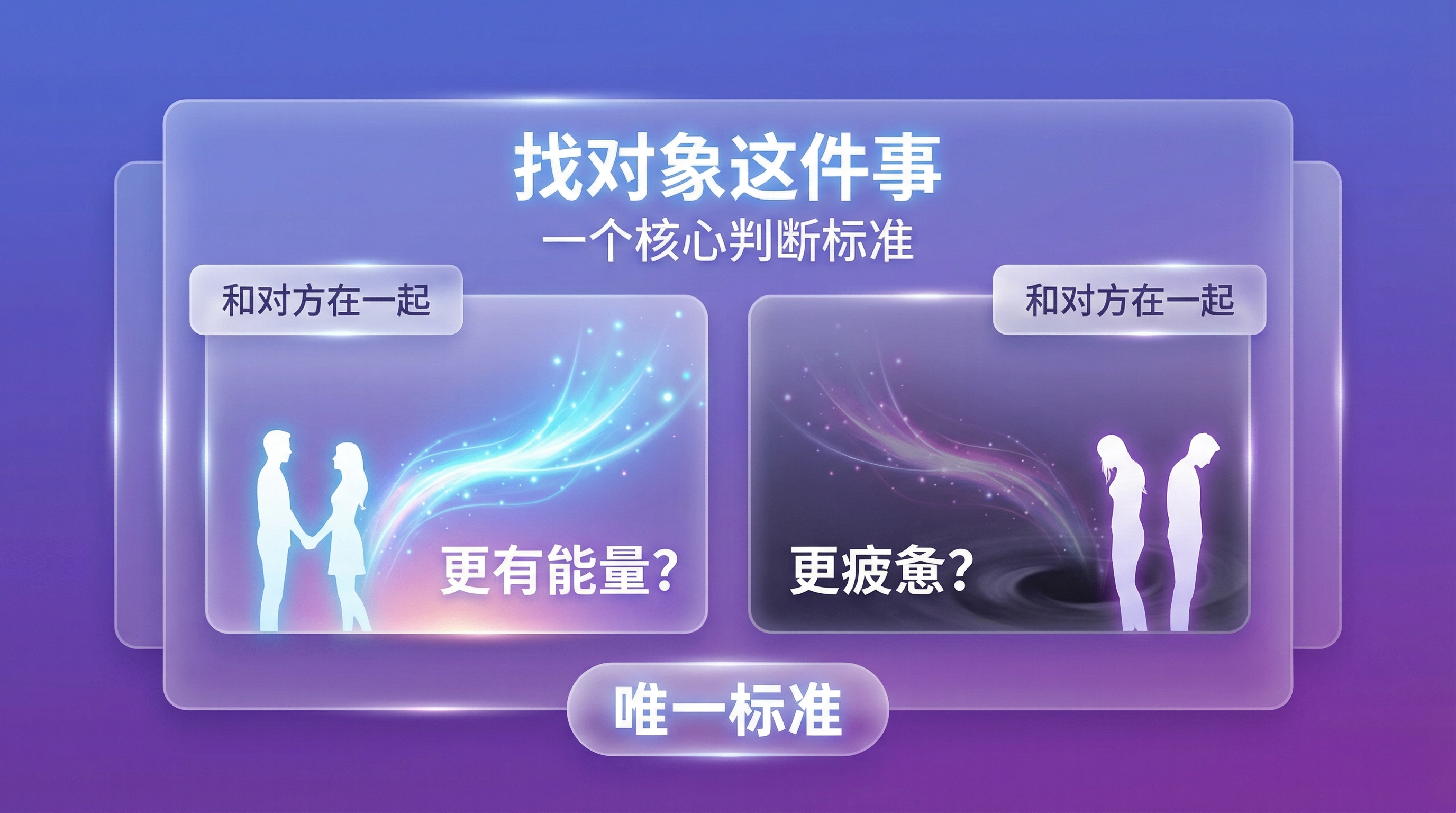
找对象这件事,我想通了一个标准
前段时间看到一个说法,觉得特别准: 真正厉害的人挑选伴侣,只看一件事——和对方在一起,你是更有能量,还是更疲惫? 不是看对方多好看、多有钱、多优秀。而是看:和这个人在一起之后,你是更自由、更松弛、更有劲头去干事情?还是更压抑、更内耗、更想逃? 这个标准听起来简单,但我觉得它比所有”高价值伴侣清单”都管用。 “对你好”不是决定性因素 很多人找对象的标准是”对我好”。 这当然重要,但问题是——“对你好”是最低要求。任何一个正常人都应该对伴侣好。把最低要求当成核心标准,很容易踩坑。 更大的问题是,恋爱期的”好”可能是表演。有些人在追你的时候送花接送嘘寒问暖,目的达成之后就变了一个人。不是所有的”好”都是真的,有些”好”是有条件的。 “我对你好,但你要听我的。”“我对你好,但你不能让我不高兴。” 这不是爱,是交易。 生命力才是核心标准 我后来觉得,真正重要的判断标准就三个问题: 第一,和这个人相处完,你是更有能量还是更累? 有些人自带能量场,跟他们聊完天你觉得充了电。有些人像一个黑洞,你的精力被源源不断地吸走。 第二,你能不能在这个人面前做真实的自己? 不需要伪装、不需要压抑、不需...

投稿 SCI,我因为漏了一个文件被退回过
辛辛苦苦写了几个月的论文,投出去当天就被退回了。 不是质量问题,是文件不齐。 编辑的回复很客气:”请补充完整后重新提交。”打开投稿系统一看——原来还需要单独上传 Title Page。 就这么一个文件,耽误了将近两周。 后来我才知道,这种事太常见了。据说超过 30% 的 SCI 投稿因为文件不齐被退回。不是论文写得不好,是基本功没做到位。 从那以后我给自己列了一份清单,每次投稿前逐项打钩。今天分享出来,希望你不要踩我踩过的坑。 五类文件,缺一类都可能被退 SCI 投稿的文件大致分五类:核心文件、图表文件、投稿信、审稿人建议、声明文件。 核心文件是入场券,少一张都进不了评审环节。包括正文(Manuscript)、标题页(Title Page)、摘要(Abstract)、关键词(Keywords)。 正文的格式要注意:双倍行距、页码标注、部分期刊还要求行号。这些看起来是小事,但格式不对编辑会直接退回。 标题页是最容易漏的。大多数期刊要求盲审,正文里不能出现作者信息,所以作者姓名、单位、通讯作者邮箱这些要单独放在 Title Page 里上传。我第一次投稿就栽在这里。 摘要一般 1...

活着是硬道理,但怎么活是个技术活
如果让我用一句话总结这两年最大的感悟,大概就是: 健康幸福地活着,活得长长久久高高兴兴,是硬硬硬的硬道理。 听起来像废话,但你真的做到了吗? 真正的痛苦和自己制造的痛苦 我后来想明白一件事:痛苦分两种。 第一种是真实的物质匮乏——吃不饱、穿不暖、交不起房租、看不起病。这种痛苦是真的,也是最优先要解决的。没有物质基础谈精神追求,是空中楼阁。 第二种是自己制造的精神痛苦——觉得别人应该按你的想法做但他没做,期待落空了,在意别人的评价了。这种痛苦本质上是你把自己的想法强加给了外界,外界没接受,你就难受。 分清这两种痛苦很重要。对第一种,想办法解决。对第二种,想办法化解。 物质基础:先确保自己能活下去 这话说得糙,但是真的。 我是一个研究生,有奖学金、有基本的生活保障。每次焦虑的时候我会提醒自己:你有一份收入,你吃饱了,你有地方住,你的基本需求是满足的。 这不是自我安慰,是在锚定一个事实——你的处境没有你情绪告诉你的那么糟糕。 马斯洛说得对:先满足底层需求,再追求高层的东西。物质基础没解决的时候,不要跟自己谈理想谈情怀。先确保稳定收入、建立紧急储蓄、买必要的保险。这些是地基。 精...
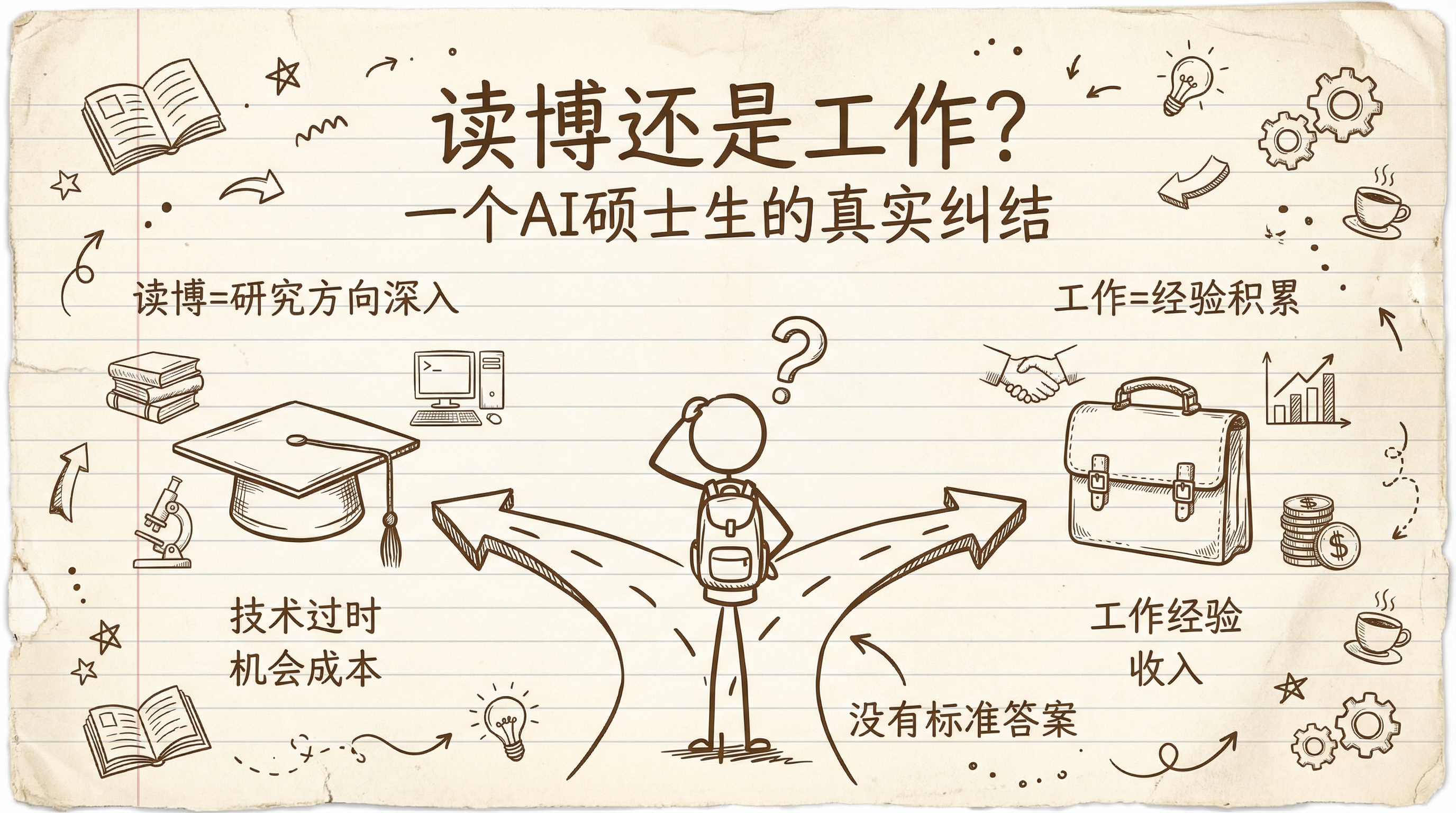
读博还是工作?一个 AI 方向硕士生的真实纠结
这个问题我想了很久。 作为一个电子信息工程的硕二学生,做计算机视觉方向,身边的人大致分两拨:一拨准备读博,一拨准备找工作。两边都有道理,两边都有风险。 我自己目前倾向读博,目标是东华大学和上海交大。但我不会告诉你”读博一定好”或者”工作一定好”——因为这取决于太多个人因素。 我只说我看到的事实,和我自己的思考。 学术界的风险,比你想象的大 AI 领域有一个很残酷的现实:技术迭代太快了。 2017 年 Transformer 出来,之前做 RNN/LSTM 的研究基本一夜过时。2022 年 ChatGPT 出来,传统 NLP 的研究范式整个被改写。2024 年 Sora 出来,视频生成领域重新洗牌。 一个博士读四到六年,而 AI 的技术范式迭代周期大概只有两到三年。这意味着你读博期间,研究方向可能被颠覆一到两次。 毕业时发现自己做的东西已经没人关心了——这不是极端情况,是真实发生过的事。 另一个问题是学术界和工业界的脱节。以强化学习为例,学术界大量论文在卷 Atari 游戏的分数——“在 100k 步的时候谁分数高”。但工业界需要的是能落地的东西:机器人控制、推荐系统...

逆天改命,改的到底是什么?
最近听到一个对”命”和”运”的解释,觉得特别通透。 命,就是当你面对一件事情的时候,按照你过往的性格和习惯会做出的行为。不假思索,自动反应——遇到冲突就回避,遇到困难就放弃,遇到机会就犹豫。这些刻在你身体里的默认反应,就是你的命。 运,是你停下来想了一想,然后做出了一个跟你平时不一样的选择。逆着本能,做出不同的行为,产生不同的结果。这就是运。 所以所谓”逆天改命”,逆的不是天,是自己的本能。改的不是命,改的是运。 命为什么难改? 因为习惯的力量太大了。 心理学研究说,人每天 40% 的行为是习惯性的——不经过思考,自动执行。你遇到一件事,大脑会下意识地调用以前的应对模式,就像自动驾驶一样。 这些模式是你十几二十年养成的。内向的人遇到社交场合就想躲,悲观的人遇到困难第一反应是”算了”,冲动的人看到机会就直接冲——不是他们不知道有更好的选择,是身体比脑子快。 而且这些模式是可预测的。你身边的人大概率能猜到你面对某件事会怎么做。别人能预测你的行为,你的结果就基本是固定的。 这就是”命是定数”的意思。 运怎么来? 运来自一个动作:暂停。 遇到事情的时候,不是立刻按习惯反应,而是停一...

人和人说话,也是要消耗 Token 的
最近听到一个说法,觉得特别准: 人和人之间的对话,也是需要消耗 Token 的。 你每天的精力就像大模型的上下文窗口——有上限。深度对话消耗大量 Token,闲聊消耗少量 Token,而大部分人的问题是:Token 花在了不重要的人身上,等到面对重要的人时,已经没余量了。 你有没有过这种体验? 白天在社群里跟一堆人聊了半天,晚上回家女朋友想跟你说说话,你一个字都不想说了。 工作中开了五个会,每个会都认真听、认真回应,到了晚上该想正事的时候,脑子一片浆糊。 朋友聚会上努力活跃气氛,回到家瘫在床上觉得被掏空了。 这不是你冷漠,也不是你社恐。是你的 Token 用完了。 深度对话和闲聊,消耗量差了好几倍 心理学研究早就说过:人每天能做深度工作的时间大概只有 3-4 小时,高质量社交的极限大概是 2-3 小时。超过这个量,质量就急剧下降。 深度对话——认真倾听、共情回应、动脑思考——消耗的精力是闲聊的三到五倍。 问题是,很多人把这些宝贵的深度 Token 花在了不重要的地方:跟陌生人在评论区争论、在无效会议上假装专注、在泛泛之交的饭局上努力表演。 等到真正重要的人需要你的时候,你已...




