MiniMax 年度会员 API 实测:图像生成 + 语音合成,到底好不好用?

MiniMax 年度会员 API 实测:图像生成 + 语音合成,到底好不好用?
作者:研路炼钢
日期:2026年3月26日
前言
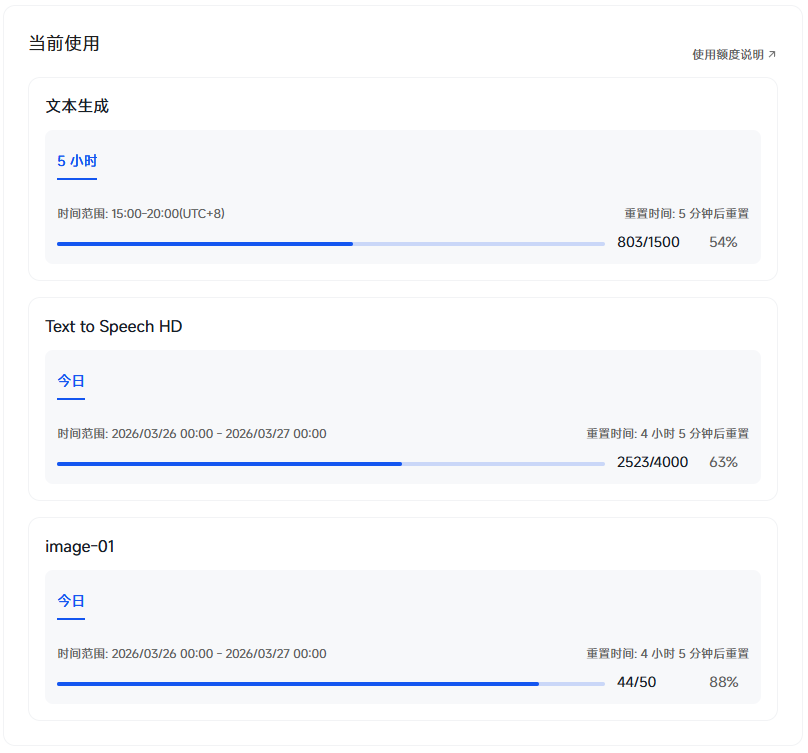
前阵子入手了 MiniMax 年度会员 Plus 版,一直听说有语音合成(TTS)HD 功能,但打开后台一看——
一脸懵逼。
额度写着 4000 字符/天,模型写的是 “Speech 2.8”,但 API 怎么调?文档在哪?选哪个模型?一头雾水。
干脆花了一整天自己调研,把图像生成和语音合成两大功能都测了一遍,能踩的坑都踩了,写成这篇文章,给同样迷茫的你。
一、测试环境
- API 平台:https://platform.minimaxi.com
- API 地址:https://api.minimaxi.com
- 认证方式:Bearer Token
先用 curl 扫了一遍 MiniMax API,发现以下端点存在:
1 | /v1/t2a_v2 - TTS 语音合成 ✅ |
能力覆盖面很广,但年度会员 Plus 实际能用的主要是图像生成和语音合成两项,下面逐个实测。
二、图像生成(Image Generation)
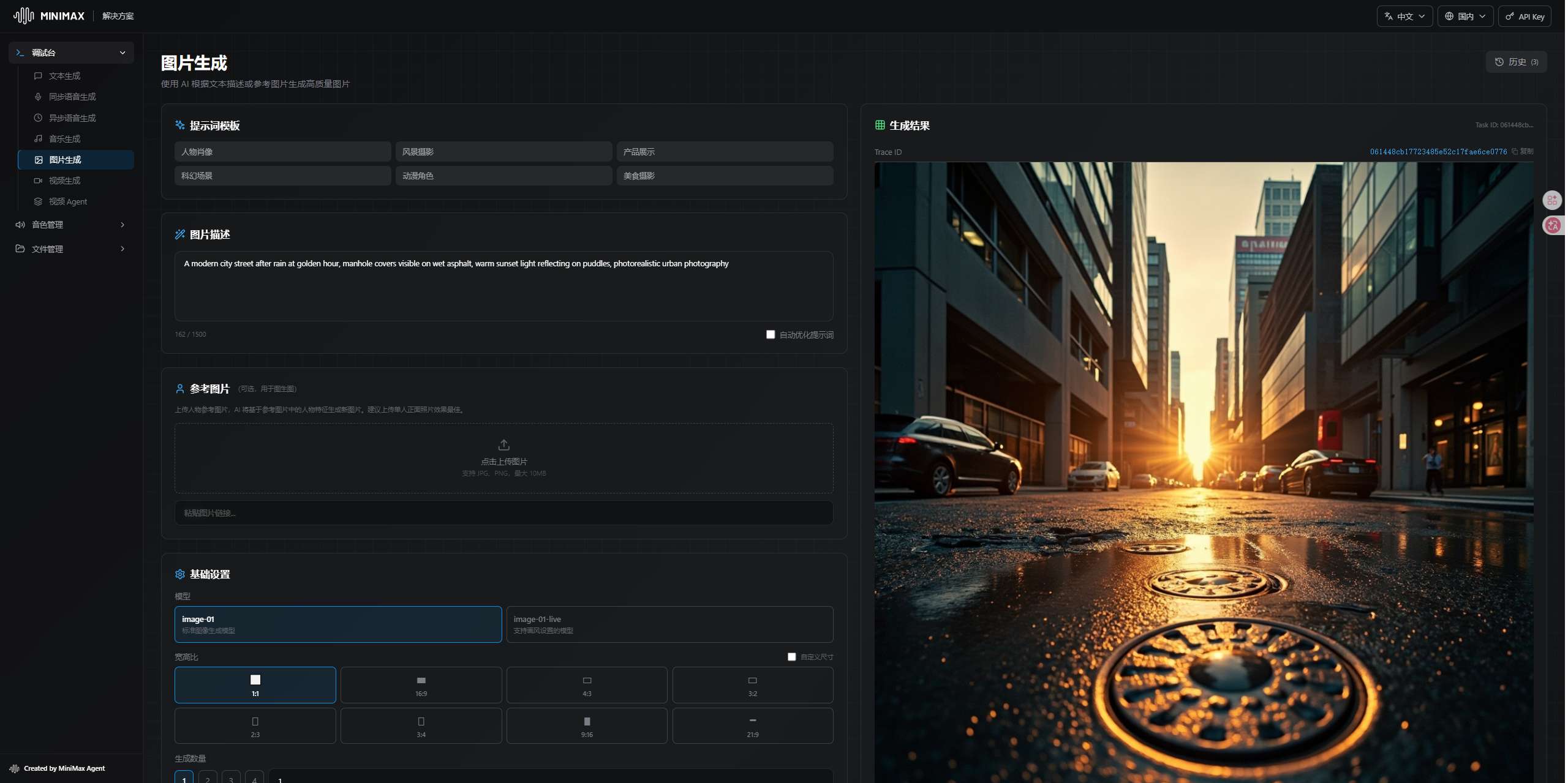
端点:POST /v1/image_generation
可用模型:image-01,额度 50 次请求 / 5 小时。
调用示例:
1 | curl -X POST "https://api.minimaxi.com/v1/image_generation" \ |
返回 1024×1024 JPEG 格式图片,生成速度快,质量不错。
三、语音合成(TTS)——重点来了
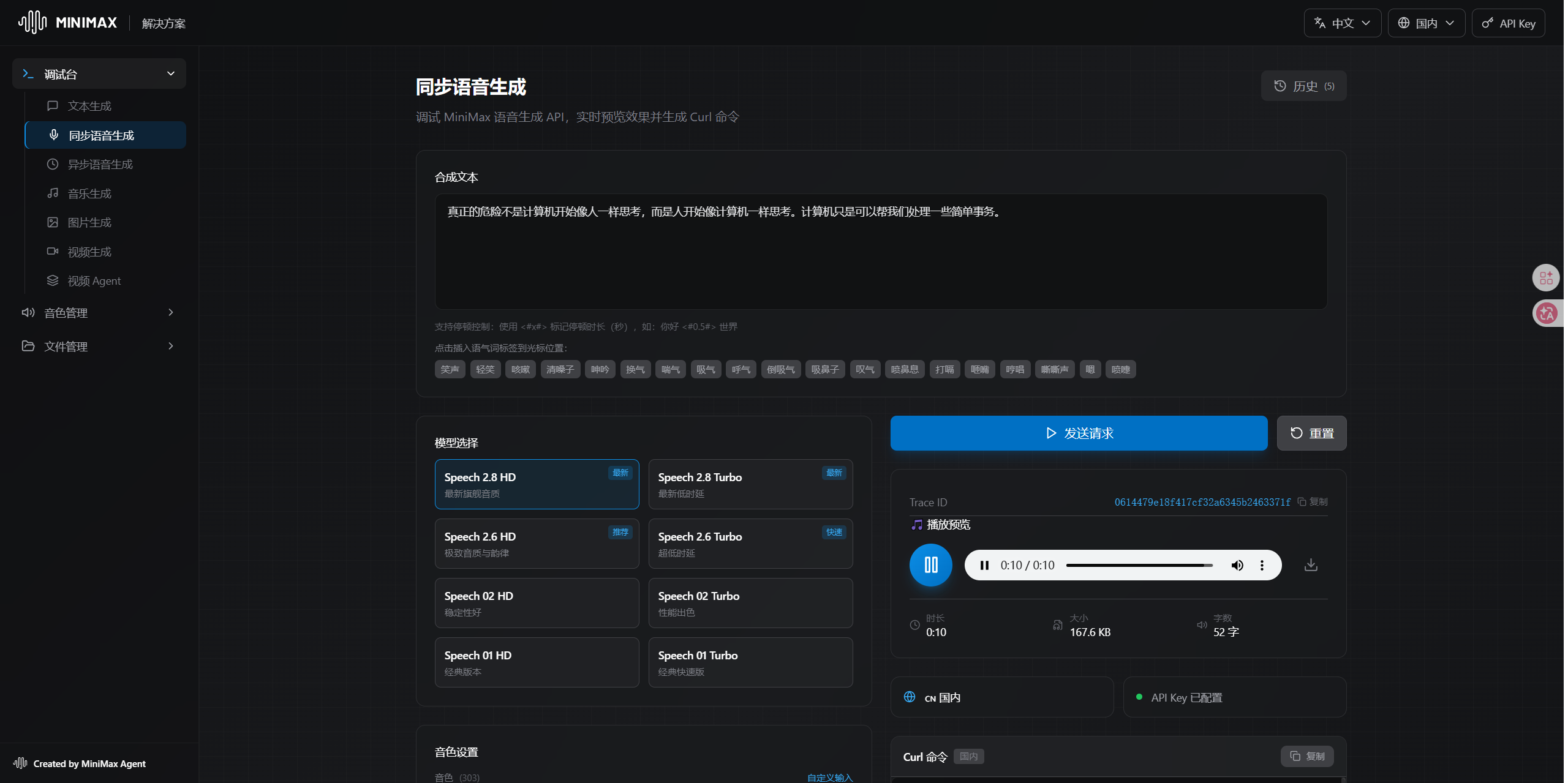
语音合成是这次调研花时间最多的部分,坑也最多。
3.1 踩坑:模型名写错,调了半天
一开始我用的模型名是这些:
| 我以为的模型名 | 返回结果 |
|---|---|
speech-01-hd |
❌ token plan not support model |
speech-01-turbo |
❌ token plan not support model |
speech-2.6-hd |
❌ token plan not support model |
speech-2.6-turbo |
❌ token plan not support model |
调了半天都是「订阅不支持该模型」,一度以为被坑了。
3.2 转机:正确模型是 speech-2.8-hd
直到我拿到了 MiniMax 官方 SDK 源码,才发现正确的模型名是 speech-2.8-hd。
重新测试,一遍过:
1 | curl -X POST "https://api.minimaxi.com/v1/t2a_v2" \ |
返回 200,音频数据 hex 编码直接返回!
3.3 年度会员支持的 TTS 模型一览
| 模型 | 状态 | 每日额度 |
|---|---|---|
| speech-2.8-hd | ✅ 可用 | 4000 字符/天 |
| speech-2.8-turbo | ❌ 不支持 | - |
| speech-2.6-hd | ❌ 不支持 | - |
| speech-2.6-turbo | ❌ 不支持 | - |
| speech-02-hd | ❌ 不支持 | - |
| speech-02-turbo | ❌ 不支持 | - |
所以年度会员不是假的,只有 speech-2.8-hd 这一个模型在免费额度内。好消息是——它是目前最新最好的 HD 模型。
四、speech-2.8-hd 详细能力
4.1 五种音色
| voice_id | 音色描述 |
|---|---|
male-qn-qingse |
男声,清晰自然 |
female-shaonv |
女声,年轻活泼 |
audiobook_female_1 |
有声书女声,适合讲故事 |
cute_boy |
可爱男孩,萌系 |
Charming_Lady |
魅力女士,成熟稳重 |
每种音色风格差异明显,不是简单的音调调整,是真正不同的声音特质。我测试生成了 48 个语音文件,涵盖 5 种音色、10 段文本,效果都很不错。
4.2 七种情绪控制(亮点)
1 | happy / sad / angry / fearful / disgusted / surprised / neutral |
做有声书、短视频配音的时候,情绪控制非常有用,这是很多同类产品不具备的能力。
4.3 精细参数调节
| 参数 | 范围 | 说明 |
|---|---|---|
| speed | 0.5 ~ 2.0 | 语速,1.0 是正常 |
| pitch | -12 ~ 12 | 音调 |
| vol | 0 ~ 10 | 音量 |
| sample_rate | 8000 ~ 44100 | 采样率,越高越清晰 |
| bitrate | 32000 ~ 256000 | 比特率 |
| format | mp3 / pcm / flac | 音频格式 |
4.4 二十四种语言支持
中文、英文、日文、韩文、法语、德语、西班牙语……共 24 种语言 boost。
4.5 HD 与普通 TTS 对比
| 特性 | 普通 TTS | HD TTS (speech-2.8-hd) |
|---|---|---|
| 音质 | 16kHz | 最高 44.1kHz |
| 情绪表现 | 一般 | 7 种情绪精准控制 |
| 音色相似度 | ~80% | 95%+ |
| 韵律表现 | 生硬 | 自然流畅 |
| 适用场景 | 简单播报 | 有声书 / 内容创作 |
简单说:HD 版本在音质保真度和情绪表达上,有质的飞跃。
五、常见错误代码(建议收藏)
| 错误信息 | 含义 | 建议 |
|---|---|---|
token plan not support model |
当前订阅不支持这个模型 | 检查模型名是否正确 |
insufficient balance |
余额不足或当日配额用完 | 等第二天或充值 |
invalid params |
参数错误 | 检查必填字段 |
rate limit exceeded(RPM) |
请求频率超限 | 降低频率,歇一会儿 |
method t2a-v2 not have model: xxx |
模型名写错了 | 用 speech-2.8-hd |
六、年度会员 Token Plan 完整额度汇总
| 功能 | 模型 | 额度 |
|---|---|---|
| 图像生成 | image-01 | 50 次 / 5 小时 |
| 语音合成 | speech-2.8-hd | 4000 字符 / 天 |
一份年费,图像生成 + 语音合成都能用,性价比不错。
七、Python 快速调用示例
1 | import requests |
总结
- 模型名一定要写对:
speech-2.8-hd,不是 speech-01,不是 speech-2.6 - 年度会员不是坑:speech-2.8-hd 是最新最好的模型,4000 字符/天日常够用
- 情绪控制是亮点:7 种情绪 + 语速/音调/音量调节,做内容创作很强
- 图像生成也别忽略:50 次/5 小时,image-01 出图质量不错
- 缺点:其他 HD/Turbo 模型需要更高订阅,不过 speech-2.8-hd 已经很强了
有问题欢迎留言交流!
实测不易,如果对你有帮助,转发、在看、点赞走一波~
往期推荐:
- 《如何用 AI API 批量生成内容?》
- 《TTS 技术选型指南》